#CARLA-SUMO Co-Simulations-Lernrahmen: Lassen Sie selbstfahrende Autos lernen, aktiv die Spur zu wechseln
1. Einleitung: Warum ist Co-Simulation nötig?
Das Training von Spurwechselstrategien für autonomes Fahren steht vor einem grundsätzlichen Widerspruch:
- CARLA bietet eine hochpräzise Fahrzeugdynamiksimulation – Motorreaktion, Reifenreibung, Aufhängungsdynamik, genau auf der physikalischen Ebene. Aber standardmäßig ist nur das Hauptfahrzeug autonom und der Hintergrundverkehr muss manuell konfiguriert werden.
- SUMO eignet sich gut für groß angelegte Verkehrsflusssimulationen – es kann problemlos Hunderte oder Tausende von Hintergrundautos generieren, um das Stau-, Verfolgungs- und Spurwechselverhalten des realen Stadtverkehrs zu simulieren. Das Fahrzeugmodell von SUMO ist jedoch makroskopisch und weist keine dynamischen Details auf.
**Beides allein reicht nicht aus. **
Wenn nur CARLA verwendet wird, ist der Hintergrundverkehr spärlich und Entscheidungen zum Spurwechsel sind weniger schwierig. Wenn Sie nur SUMO verwenden, ist das Fahrzeugverhalten zu „regelmäßig“ und es ist unmöglich, die tatsächliche dynamische Reaktion zu erlernen.
Infolgedessen wurde Co-Simulation zur optimalen Lösung – CARLA verwaltet die Dynamik des Hauptfahrzeugs, SUMO verwaltet den Hintergrundverkehrsfluss und synchronisiert den Status in Echtzeit über das TraCI-Protokoll. Dies ist der Kernentwurf dieses Projekts.
2. Systemarchitektur: Wie arbeiten Dual-Emulatoren zusammen?
2.1 Parallele Architektur
CARLA und SUMO laufen als zwei unabhängige Prozesse und kommunizieren über eine Python-Schnittstelle (CARLA Python API + TraCI). Der Datenfluss des gesamten Systems ist wie folgt:
┌─────────────┐ TraCI ┌─────────────┐
│ SUMO │ ←────────────→ │ CARLA │
│ (交通流) │ 状态同步 │ (动力学) │
└─────────────┘ └─────────────┘
↑ ↑
│ │
└─────── 主车状态双向同步 ───────┘
(BridgeHelper)- SUMO ist für die Generierung, Bewegung, den Spurwechsel von Hintergrundfahrzeugen und die Entscheidungsfindung auf der Ebene der Verkehrsregeln verantwortlich.
- CARLA ist für die präzise dynamische Reaktion des Ego-Fahrzeugs verantwortlich – die tatsächlichen physikalischen Effekte von Beschleunigung, Bremsen und Lenken.
- BridgeHelper ist der „Übersetzer“ der beiden Welten, verantwortlich für die Koordinatensystemkonvertierung (linkes Koordinatensystem ↔ rechtes Koordinatensystem), Positionsübersetzung und Orientierungswinkelumkehr.
2.2 Zeitsynchronisationsmechanismus
Der Kern der Co-Simulation ist eine streng sequentielle Synchronisationsfunktion „_sync_world“:
def _sync_world(self):
# 1. 推进 SUMO,获取所有交通参与者状态
sumo_sim.tick()
# 2. SUMO → CARLA:同步背景车辆位置
self._sync_sumo_to_carla()
# 3. 推进 CARLA,应用主车控制指令
carla_sim.tick()
# 4. CARLA → SUMO:同步主车位置回 SUMO(幽灵车)
self._sync_carla_to_sumo()Jeder Simulationsschritt dauert 0,1 Sekunden (STEP_LENGTH = 0,1), wodurch Genauigkeit und Effizienz in Einklang gebracht werden.
2.3 Hauptkontrollmechanismus des FahrzeugsDas Masterfahrzeug übernimmt über CARLAs Traffic Manager (TM). TM konfiguriert mehrere Schlüsselparameter:
- „set_synchronous_mode(True)“ – synchroner Modus, um sicherzustellen, dass TM mit dem Simulationsschritt synchronisiert ist
- Deaktivieren Sie den automatischen Spurwechsel. Entscheidungen zum Spurwechsel werden zu 100 % durch die Reinforcement-Learning-Richtlinie gesteuert -Folgeabstand 3,0 Meter – einen sicheren Folgeabstand einhalten
- Ampeln ignorieren – Entscheidungsszenarien vereinfachen
Wenn die Richtlinie eine Spurwechselaktion ausgibt, senden Sie einen erzwungenen Spurwechselbefehl über „force_lane_change“ und legen Sie eine Spurwechsel-Abkühlzeit von 40 Schritten (ca. 4 Sekunden) fest.
3. Verstärkungslernalgorithmus: PPO
3.1 Warum PPO wählen?
Dieses Projekt verwendet den Algorithmus Proximal Policy Optimization (PPO), der von der Stable-Baselines3-Bibliothek implementiert wird. Hauptgründe für die Wahl von PPO:
- Hohe Stabilität: Beschränken Sie den Umfang von Richtlinienaktualisierungen durch den Clip-Mechanismus, um Leistungsabstürze durch ein einzelnes zu großes Update zu vermeiden.
- Hyperparameter Robust: Konvergenz kann ohne eine große Anzahl von Parameteranpassungen erreicht werden, geeignet für die Projektimplementierung
- Unterstützt kontinuierlichen/diskreten gemischten Raum: Obwohl dieses Projekt Aktionen diskretisiert, unterstützt das PPO-Framework natürlich eine komplexere Aktionsraumerweiterung
Die Zielfunktion von PPO ist:
Dabei ist
3.2 Netzwerkstruktur
Das Richtliniennetzwerk verwendet MlpPolicy (mehrschichtiges Perzeptron):
- Shared Feature Layer: Zwei vollständig verbundene Schichten mit 128 Einheiten + ReLU-Aktivierung
- Richtlinien-Header: Gibt die logarithmische Wahrscheinlichkeit einer dreidimensionalen diskreten Aktion aus
- Wert-Header: Schätzung des Ausgabestatuswerts
Hyperparameter trainieren:| Parameter | Wert | |------|-----| | Lernrate | 3e-4 | | GAE λ | 0,95 | | Abzinsungsfaktor γ | 0,99 | | Anzahl der Schritte pro Runde n_steps | 2048 | | Chargengröße | 64 | | Entropiekoeffizient ent_coef | 0,01 |
4. Aktionsraum und Beobachtungsraum
4.1 Aktionsraum (dreidimensional diskret)
| Aktion | Wert | Verhalten |
|---|---|---|
| Spur halten | 0 | Fahren Sie mit konstanter Geschwindigkeit auf der aktuellen Spur |
| Spurwechsel nach links | 1 | Spurwechsel auf die linke Spur einleiten |
| Spurwechsel nach rechts | 2 | Spurwechsel auf die rechte Spur einleiten |
4.2 Beobachtungsraum (14-dimensionaler kontinuierlicher Vektor)
Der Beobachtungsvektor enthält drei Arten von Informationen:
Hauptfahrzeugstatus (3D)
- Längsgeschwindigkeit
(normalisiert) - Quergeschwindigkeit
(normalisiert) - Soll-Reisegeschwindigkeit (normalisiert, TARGET_SPEED = 50 km/h)
Umfeldwahrnehmung des Fahrzeugs (10 Dimensionen) Bei einer 5-Kanal-Sensorkonfiguration gibt jeder Kanal „nächste Fahrzeugentfernung“ + „Relativgeschwindigkeit“ zurück:
[左后] [左前]
↑
[后] ←—— [主车] ——→ [前]
↓
[右后] [右前]Straßeninformationen (1D)
can_l: ob die linke Spur geändert werden kann (Boolean)can_r: ob die rechte Spur geändert werden kann (Boolean)st_code: Spurwechsel-Kühlstatus
5. Design der Belohnungsfunktion
Die Belohnungsfunktion ist die zentrale Triebkraft des politischen Lernens. Dieses Projekt verwendet ein gemischtes Design aus dichten Belohnungen und spärlichen Anreizen:
5.1 Belohnungen für jede Komponente
Geschwindigkeitsbonus (r_speed)
Bei Erreichen der Zielgeschwindigkeit von 50 km/h beträgt die Belohnung 1,0; Bei niedrigeren Geschwindigkeiten ist die Belohnung geringer.
Staustrafe
Dies ist die Hauptantriebskraft, die den Agenten dazu bringt, aktiv die Spur zu wechseln – es werden weiterhin Punkte abgezogen, wenn er hinter einem langsameren Fahrzeug eingeklemmt wird.Belohnung für erfolgreichen Spurwechsel
Ein Spurwechsel gilt nur dann als erfolgreich, wenn: innerhalb von 35 Schritten nach Abschluss der Spurwechselkühlung ein Spurwechsel erkannt wird. Hohe Belohnungen stellen eine starke Assoziation von „Spurwechsel → Erfolg“ her.
Sicherheitsstrafe
Kollisionen sind Hochspannungsleitungen und unter keinen Umständen akzeptabel.
5.2 Belohnungssignalanalyse
Warum ist es so konzipiert?
Die Staustrafe ist auf nicht zu hoch (-0,5) eingestellt, denn wenn sie zu hoch ist, würde der Agent „eher einen Unfall machen, als die Spur zu wechseln“; und die Kollisionsstrafe ist auf extrem hoch (-50) eingestellt, da die Sicherheit Vorrang vor allem anderen haben muss. Durch die gewichtete Mehrkomponentenkombination lernt die Strategie schließlich, unter der Prämisse der Sicherheit aktiv die Spur zu wechseln, um Staus zu vermeiden.
6. Trainingsergebnisse und Analyse
6.1 Trainingskonfiguration
- Karte: CARLA Town06 (Stadtstraße, zweispurig, mehrspurig)
- Simulationsschritt: 0,1 Sekunden
- Zielanzahl der Trainingsschritte: 1 Million Schritte (1 Mio. Schritte)
- Gerät: CPU-Training (GPU-Beschleunigung profitiert hauptsächlich von der Parallelität der Physiksimulation)
- CHECKPOINT SAVE: Alle 10.000 Schritte speichern
6.2 Trainingskurve
Nach 270.000 Schritten Training (entspricht ca. 7,5 Stunden) hat der Agent klare Spurwechselfähigkeiten bewiesen:
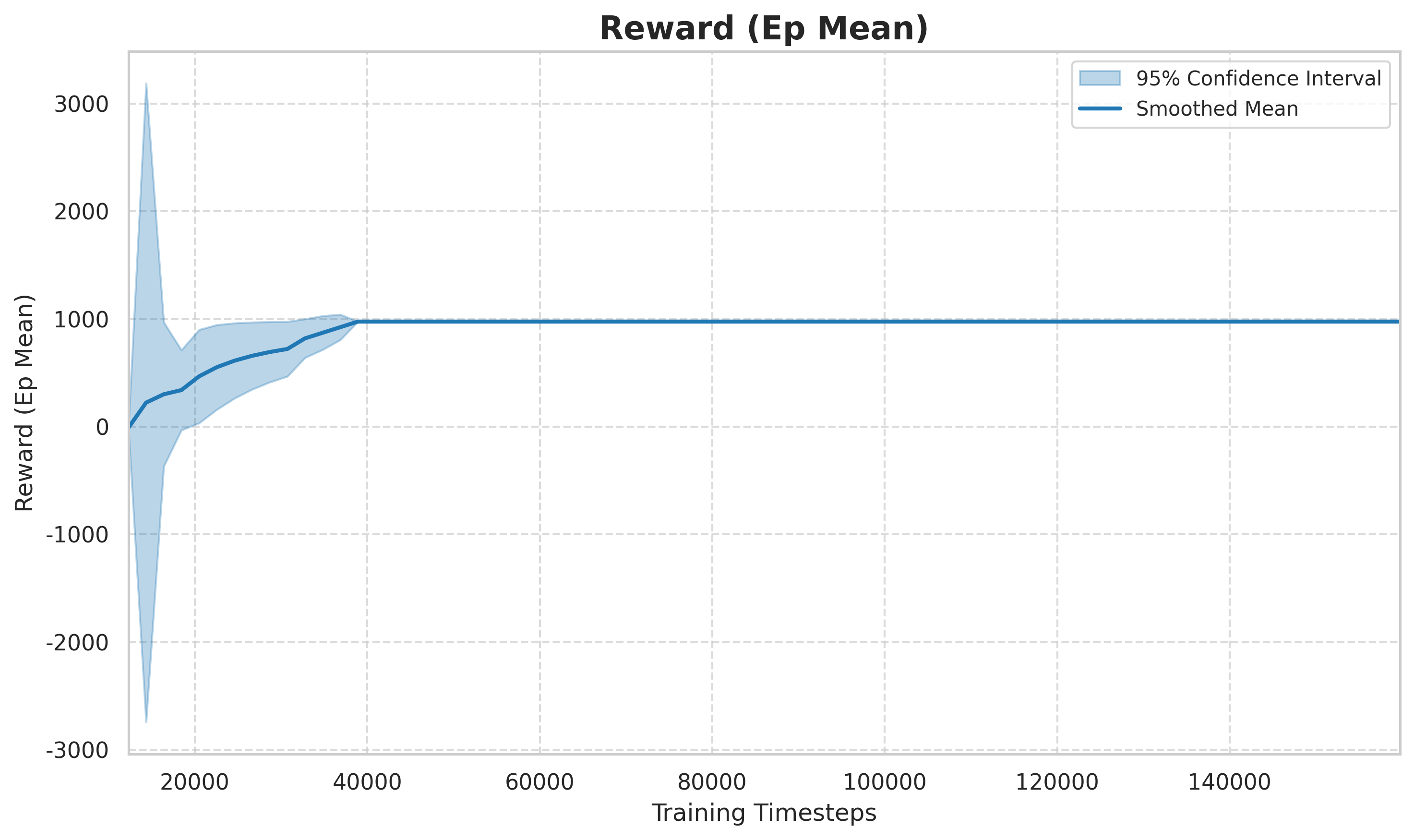
Abbildung: Die durchschnittliche Belohnung pro Episode (Mittelwert der Episodenbelohnung) ändert sich mit der Anzahl der Trainingsschritte. In der frühen Phase (0 bis 50.000 Schritte) schwankt die Belohnung stark und der Agent befindet sich in der zufälligen Erkundungsphase. In der mittleren Phase (50.000 bis 150.000 Schritte) steigt die Belohnung schnell an und die Strategie lernt allmählich, die Spur zu wechseln, um Belohnungen mit höherer Geschwindigkeit zu erhalten. Im späteren Stadium (mehr als 150.000 Schritte) tendiert es zur Konvergenz und die Strategie liegt nahe an der suboptimalen Lösung.
6.3 Wertverlust und Strategieverlust
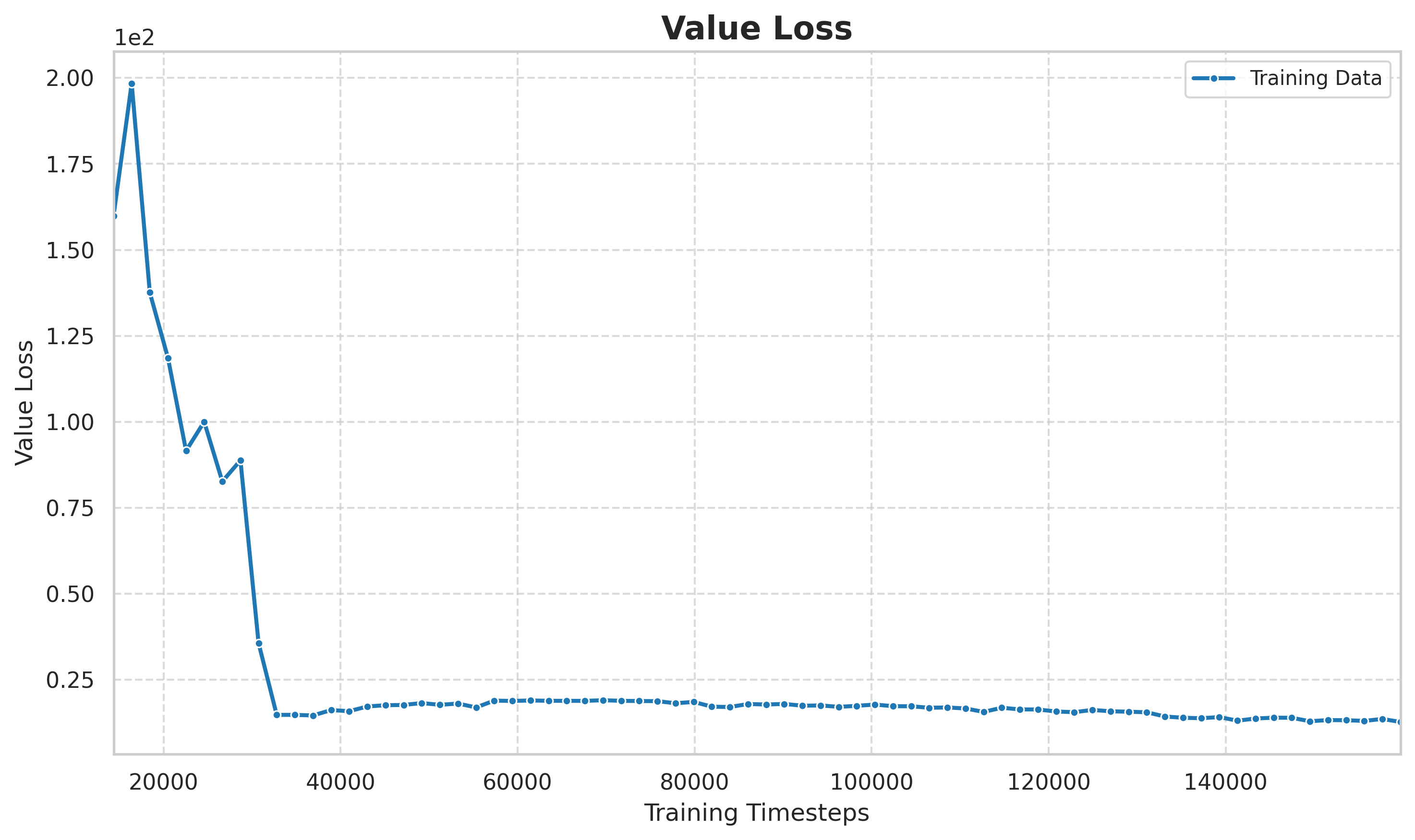 > Abbildung: Wertverlust ändert sich mit der Anzahl der Trainingsschritte. Der anfängliche Verlust ist hoch und das Wertschöpfungsnetzwerk lernt immer noch, den Zustandswert abzuschätzen. Der Verlust in der mittleren und späteren Phase stabilisiert sich auf einem niedrigen Niveau, was darauf hindeutet, dass die Wertschätzung tendenziell genau ist und eine zuverlässige Basislinie für die Vorteilsfunktion bietet.
> Abbildung: Wertverlust ändert sich mit der Anzahl der Trainingsschritte. Der anfängliche Verlust ist hoch und das Wertschöpfungsnetzwerk lernt immer noch, den Zustandswert abzuschätzen. Der Verlust in der mittleren und späteren Phase stabilisiert sich auf einem niedrigen Niveau, was darauf hindeutet, dass die Wertschätzung tendenziell genau ist und eine zuverlässige Basislinie für die Vorteilsfunktion bietet.
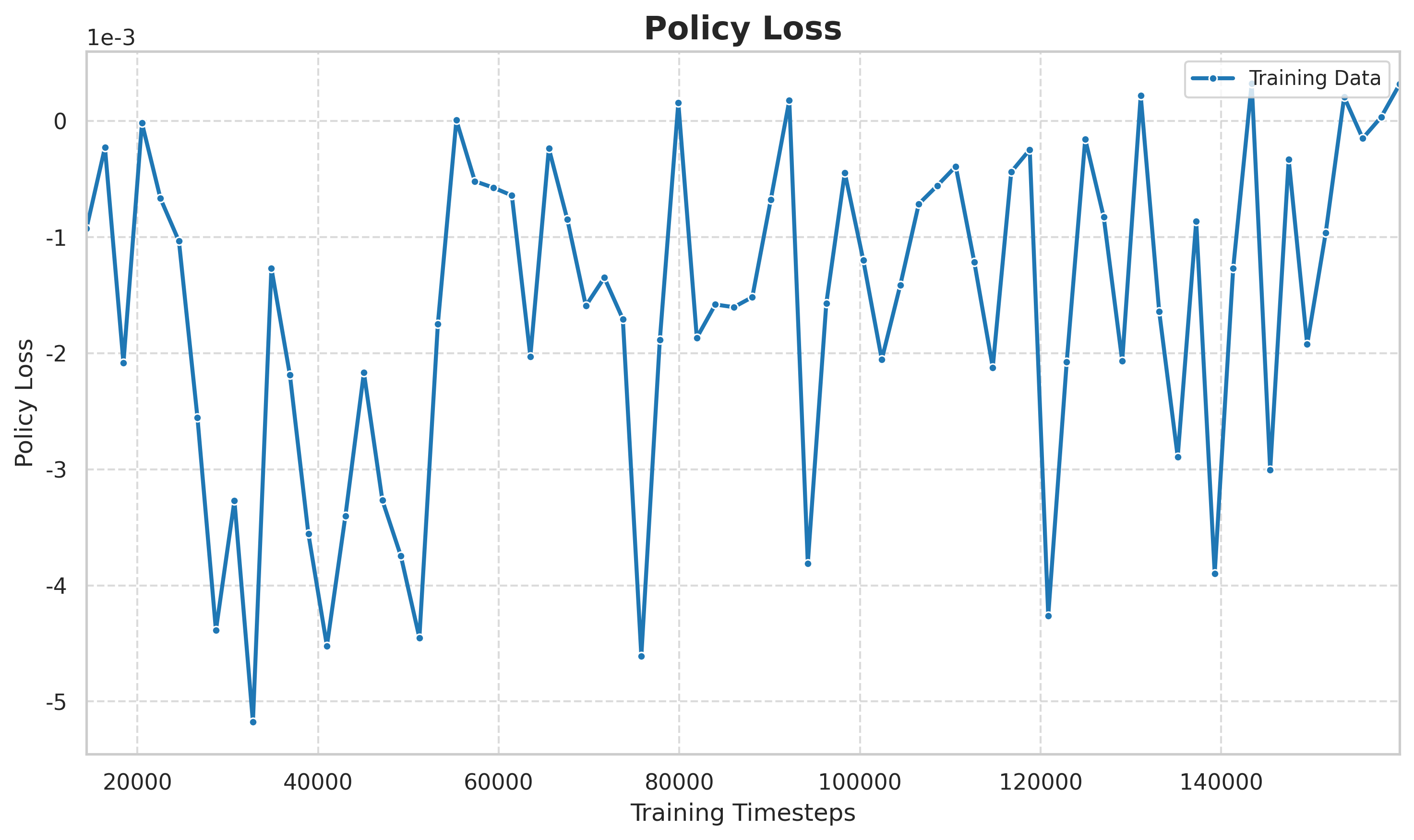
Abbildung: Policenverlustkurve. Der Strategieverlust von PPO spiegelt direkt die Richtung und das Ausmaß der Strategieaktualisierung wider, und es ist ersichtlich, dass die Strategie zwischen Exploration und Ausbeutung dynamisch angepasst wird.
6.4 Geschwindigkeitsvergleichsanalyse
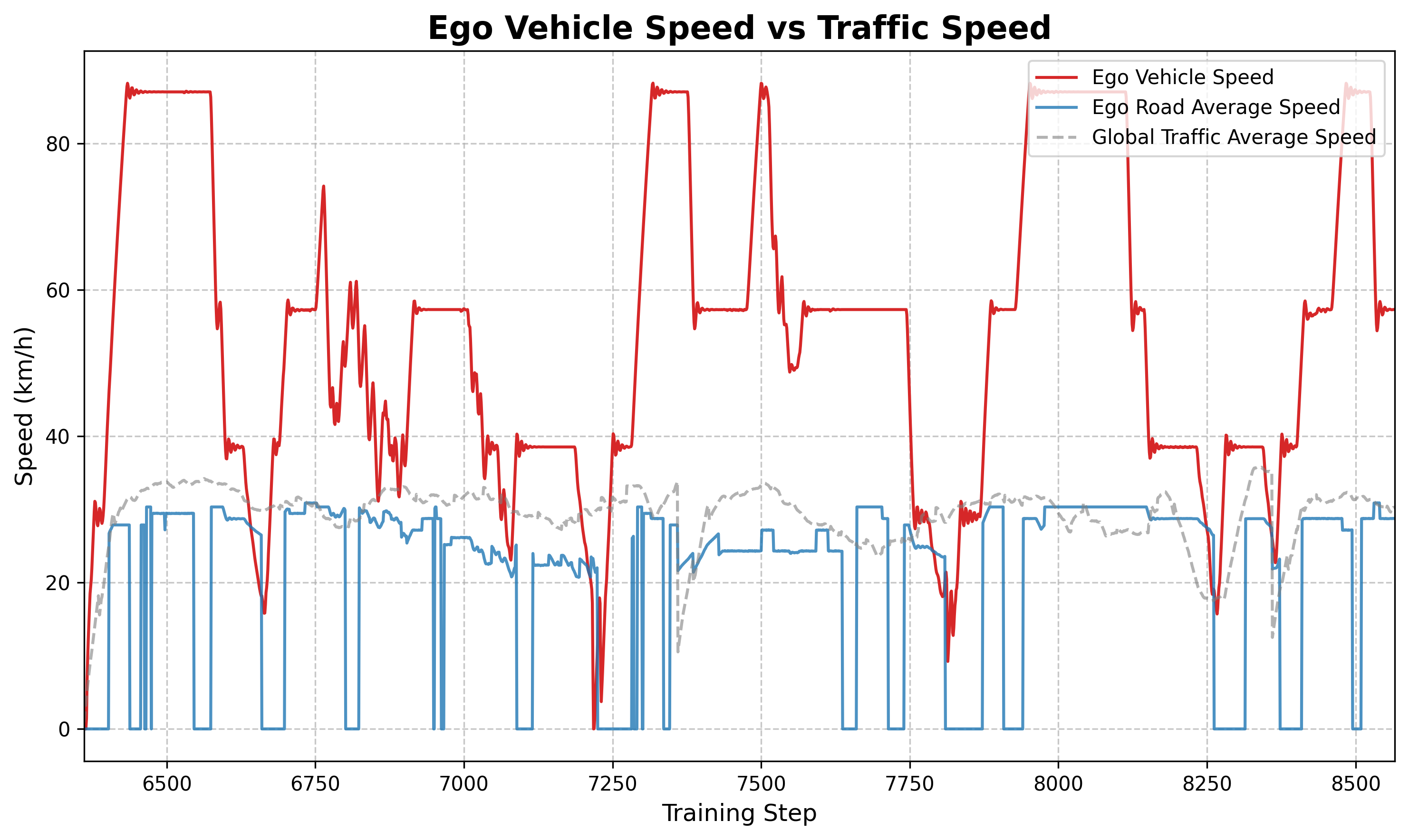
Abbildung: Vergleich der Hauptfahrzeuggeschwindigkeit (orange) mit der durchschnittlichen Straßengeschwindigkeit (blau). Es ist zu beobachten, dass die Gesamtgeschwindigkeit des Hauptfahrzeugs höher ist als die Durchschnittsgeschwindigkeit des Verkehrsflusses, was darauf hindeutet, dass die Strategie gelernt hat, aktiv Hochgeschwindigkeitsspuren zu finden oder Staus bei niedriger Geschwindigkeit zu beseitigen.
6.5 Analyse der Spurwechselfrequenz
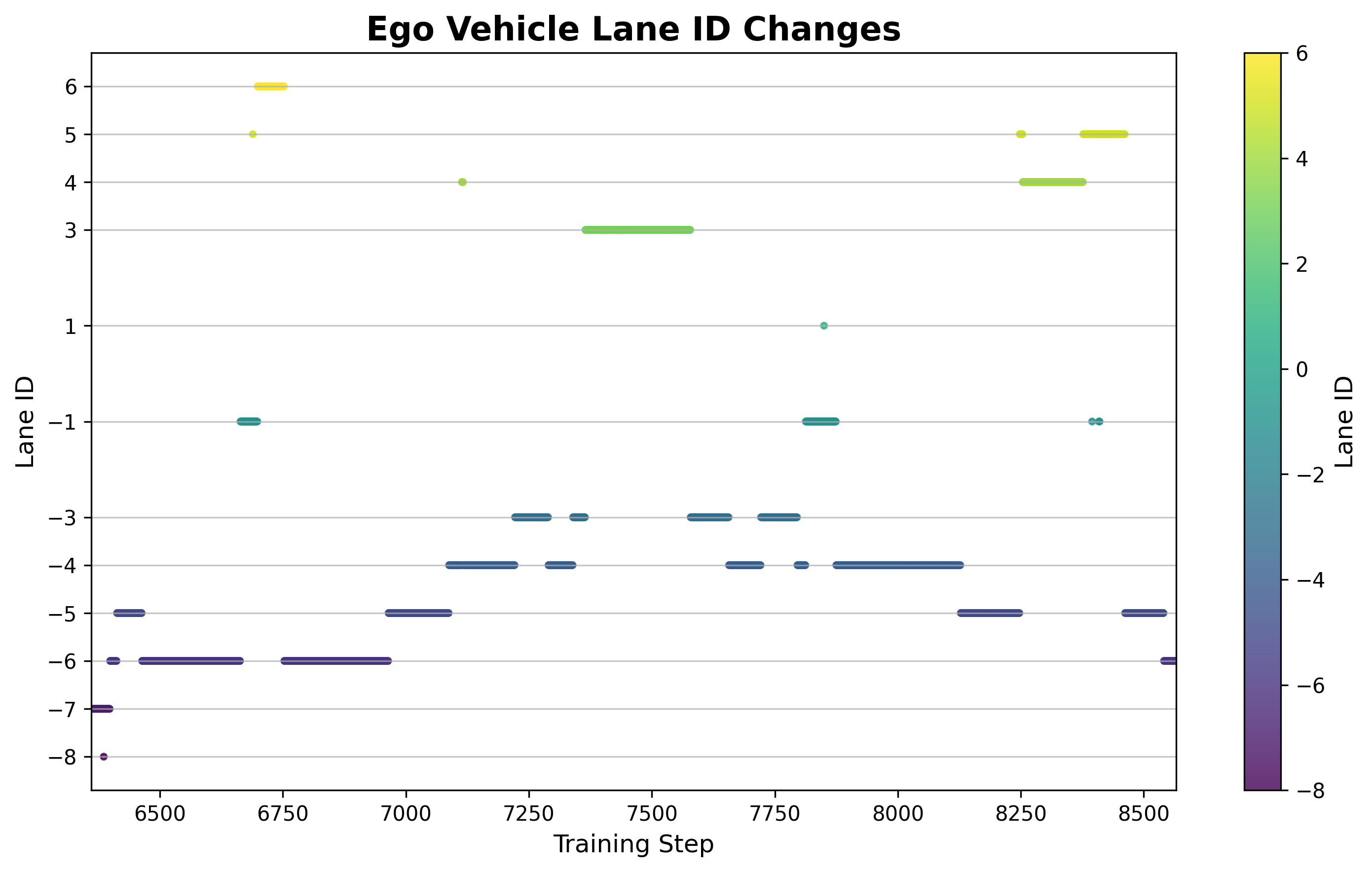
Abbildung: Veränderungen der kumulierten Anzahl an Spurwechseln während des Trainings. In der Anfangsphase waren Spurwechsel häufig, aber ineffizient (eine große Anzahl fehlgeschlagener Spurwechsel). In der mittleren und späten Phase wurden die Spurwechsel reduziert, die Erfolgsquote jedoch deutlich verbessert. Die Strategie lernte, bei Bedarf die Spur zu wechseln, anstatt blind die Spur zu wechseln.
6.6 Gespeicherte Kontrollpunkte
Das Projekt speichert 30 Checkpoints im Verzeichnis „checkpoints/“ und deckt den gesamten Trainingsprozess von 10.000 bis 270.000 Schritten ab:
ppo_carla_autodrive_10006_steps.zip
ppo_carla_autodrive_20253_steps.zip
ppo_carla_autodrive_30253_steps.zip
...
ppo_carla_autodrive_270489_steps.zipJeder Checkpoint-Schritt kann für die Wiederherstellung nach Unterbrechungen und das Strategievergleichsexperiment verwendet werden.
7. Details zur Schlüsselcode-Implementierung
7.1 BridgeHelper: Koordinatenkonvertierung
CARLA verwendet ein linkshändiges Koordinatensystem (X vorne, Y rechts, Z oben), SUMO verwendet ein rechtshändiges Koordinatensystem und die beiden Achsen sind entgegengesetzt. BridgeHelper implementiert diese Konvertierung:
# 位置转换:SUMO → CARLA
carla_location = carla.Location(
x=sumo_x,
y=-sumo_y, # Y 轴取反
z=0.5
)
# 朝向角转换
carla_rotation = carla.Rotation(
pitch=0,
yaw=math.degrees(-sumo_angle), # 角度取反
roll=0
)7.2 Deadlock-Erkennung und -Bereinigung
Hintergrundautos in SUMO können aufgrund von roten Ampeln, Staus usw. in einer Sackgasse stecken bleiben. Dieses Projekt implementiert eine intelligente Deadlock-Erkennung:
def _check_and_remove_deadlock(self, vehicle_id):
speed = traci.vehicle.getSpeed(vehicle_id)
wait_time = traci.vehicle.getAccumulatedWaitingTime(vehicle_id)
if speed < 0.1:
if self._is_at_red_light(vehicle_id) and wait_time > 120:
traci.vehicle.remove(vehicle_id) # 红灯等待超时,移除
elif wait_time > 10:
traci.vehicle.remove(vehicle_id) # 非红灯死锁,快速清理7.3 Benutzerdefinierter Rückruf: TrafficLoggerCallbackWährend des Trainingsprozesses werden Verkehrsdaten zur anschließenden Analyse automatisch im CSV-Format aufgezeichnet:
class TrafficLoggerCallback(BaseCallback):
def _on_step(self) -> bool:
infos = self.locals["infos"][0]
self.writer.writerow([
self.num_timesteps,
infos.get('ego_speed_kmh', 0.0),
infos.get('average_speed', 0.0),
infos.get('ego_road_avg_speed', 0.0),
infos.get('current_lane_id', -1)
])
return True8. Übersicht über die Projektstruktur
carlaSumoRL/
├── assets/ # SUMO 地图配置、Town06 路网
│ ├── Town06.rou.xml # 交通流生成配置
│ ├── Town06.net.xml # SUMO 路网定义
│ ├── town06.sumocfg # SUMO 仿真配置文件
│ └── *.png # 可视化结果图
├── core/ # 核心仿真逻辑
│ ├── bridge_helper.py # 坐标系转换(368行)
│ ├── carla_simulation.py # CARLA 仿真控制(186行)
│ ├── sumo_simulation.py # SUMO 仿真控制(517行)
│ └── constants.py # 常量定义
├── envs/
│ └── carla_sumo_env.py # Gym 环境定义(469行)
├── checkpoints/ # 30个训练检查点
├── ppo_carla_tensorboard/ # TensorBoard 日志
├── train_ppo.py # 训练入口
├── test_ppo.py # 测试入口
├── plot_training_curve.py # 训练曲线可视化
├── plot_metrics.py # 交通数据分析
└── traffic_log.csv # 实时交通数据日志9. Einschränkungen und zukünftige Arbeit
Aktuelle Einschränkungen
- Begrenzter Beobachtungsraum: Es wird nur ein 5-Kanal-Strahlensensor verwendet, visuelle Eingaben werden nicht verwendet und die sensorischen Informationen sind in Hochgeschwindigkeitsszenen unzureichend.
- Single-Master-Fahrzeugszenario: Die Zusammenarbeit mehrerer Agenten wird noch nicht unterstützt und das interaktive Spiel, bei dem mehrere Fahrzeuge gleichzeitig die Spur wechseln, wurde nicht modelliert.
- SUMO-Fahrzeugverhalten ist einfach: Das Hintergrundauto verwendet das standardmäßige IDM-Autoverfolgungsmodell und es fehlt die Unterscheidung zwischen aggressivem und konservativem Fahrstil.
- Die Entscheidung zum Spurwechsel hängt von der Abkühlzeit ab: Ein Spurwechsel im realen Fahrbetrieb erfordert eine mehrstufige Koordination von Wahrnehmung, Entscheidung und Ausführung, und das aktuelle Modell wurde stark vereinfacht.
Zukünftige Richtungen
- Einführung in die Bildeingabe: Verwenden Sie CNN oder Vision Transformer, um Fahrzeugkameradaten zu verarbeiten und eine End-to-End-Vision-Strategie umzusetzen
- Multi-Agenten-Erweiterung: Führen Sie mehrere selbstfahrende Hauptfahrzeuge ein, um interaktive Spiele und Konfrontationsszenarien zu studieren
- Kursverlauf: Allmählicher Übergang von einfachen Szenarien (leere Straßen) zu komplexen Szenarien (dichtes Verkehrsaufkommen, Zusammenführung von Rampen)
- Real Road Verification: Migrieren Sie die trainierte Strategie auf das Carla_ROS-Framework und verifizieren Sie sie auf einem realen Fahrzeug oder einer Hardware-in-the-Loop-Plattform
10. Zusammenfassung
Dieses Projekt implementiert vollständig ein CARLA-SUMO-kollaboratives Simulations- + PPO-Verstärkungslernen-Trainingsrahmen für den Spurwechsel beim autonomen Fahren. Durch die Zusammenarbeit zweier Simulatoren wird nicht nur die Authentizität der Hauptfahrzeugdynamik gewährleistet, sondern auch die Vielfalt und Herausforderung des Hintergrundverkehrsflusses.
Die Größe des Projektcodes beträgt etwa 1540 Zeilen mit einer klaren Struktur, die den gesamten Schulungs-, Test- und Visualisierungsprozess abdeckt, und 30 Prüfpunkte wurden für die Reproduktion und sekundäre Entwicklung gespeichert. Wenn Sie sich für die Planung autonomer Fahrentscheidungen und die Anwendung von Reinforcement Learning in Verkehrsszenarien interessieren, ist dieses Framework ein guter Ausgangspunkt.
Projektadresse: /home/tartlab/project/outwork/carlaSumoRL/
Autor: Kagura Tart | 15.04.2026