#CARLA-SUMO Cadre d’apprentissage par renforcement par cosimulation : laissez les voitures autonomes apprendre à changer activement de voie
1. Introduction : Pourquoi la co-simulation est-elle nécessaire ?
La formation aux stratégies de changement de voie de conduite autonome se heurte à une contradiction fondamentale :
- CARLA fournit une simulation haute fidélité de la dynamique du véhicule : réponse du moteur, friction des pneus, dynamique de la suspension, précise au niveau physique. Mais par défaut, seul le véhicule principal est autonome et le trafic en arrière-plan doit être configuré manuellement.
- SUMO est efficace pour la simulation de flux de circulation à grande échelle : il peut facilement générer des centaines ou des milliers de voitures en arrière-plan pour simuler les comportements de congestion, de suivi et de changement de voie du trafic urbain réel. Mais le modèle de véhicule de SUMO est macroscopique et manque de détails dynamiques.
**L’un ou l’autre seul ne suffit pas. **
Si seul CARLA est utilisé, le trafic de fond est clairsemé et les décisions de changement de voie sont moins difficiles. Si vous utilisez uniquement SUMO, le comportement du véhicule est trop « régulier » et il est impossible d’apprendre la véritable réponse dynamique.
En conséquence, la Co-simulation est devenue la solution optimale : CARLA gère la dynamique du véhicule principal, SUMO gère le flux de trafic en arrière-plan et synchronise l’état en temps réel via le protocole TraCI. C’est la conception centrale de ce projet.
2. Architecture système : Comment les émulateurs doubles collaborent-ils ?
2.1 Architecture parallèle
CARLA et SUMO fonctionnent comme deux processus indépendants et communiquent via une interface Python (CARLA Python API + TraCI). Le flux de données de l’ensemble du système est le suivant :
┌─────────────┐ TraCI ┌─────────────┐
│ SUMO │ ←────────────→ │ CARLA │
│ (交通流) │ 状态同步 │ (动力学) │
└─────────────┘ └─────────────┘
↑ ↑
│ │
└─────── 主车状态双向同步 ───────┘
(BridgeHelper)- SUMO est responsable de la génération, du mouvement, du changement de voie des véhicules d’arrière-plan et de la prise de décision au niveau des règles de circulation.
- CARLA est responsable de la réponse dynamique précise du véhicule Ego - les effets physiques réels de l’accélération, du freinage et de la direction.
- BridgeHelper est le « traducteur » des deux mondes, responsable de la conversion du système de coordonnées (système de coordonnées gauche ↔ système de coordonnées droite), de la translation de position et de l’inversion de l’angle d’orientation.
2.2 Mécanisme de synchronisation de l’heure
Le cœur de la co-simulation est une fonction de synchronisation strictement séquentielle _sync_world :
def _sync_world(self):
# 1. 推进 SUMO,获取所有交通参与者状态
sumo_sim.tick()
# 2. SUMO → CARLA:同步背景车辆位置
self._sync_sumo_to_carla()
# 3. 推进 CARLA,应用主车控制指令
carla_sim.tick()
# 4. CARLA → SUMO:同步主车位置回 SUMO(幽灵车)
self._sync_carla_to_sumo()Chaque étape de simulation dure 0,1 seconde (STEP_LENGTH = 0,1), équilibrant précision et efficacité.
2.3 Mécanisme de commande principal du véhiculeLe véhicule maître prend le relais via le Traffic Manager (TM) de CARLA. TM configure plusieurs paramètres clés :
set_synchronous_mode(True)— mode synchrone pour garantir que TM est synchronisé avec l’étape de simulation- Désactiver le changement de voie automatique - les décisions de changement de voie sont contrôlées à 100 % par la politique d’apprentissage par renforcement -Distance de suivi de 3,0 mètres - maintenir une distance de suivi sécuritaire
- Ignorez les feux de circulation - simplifiez les scénarios de prise de décision
Lorsque la politique génère une action de changement de voie, envoyez une commande de changement de voie forcé via « force_lane_change » et définissez un temps de refroidissement de changement de voie de 40 étapes (environ 4 secondes).
3. Algorithme d’apprentissage par renforcement : PPO
3.1 Pourquoi choisir PPO ?
Ce projet utilise l’algorithme Proximal Policy Optimization (PPO), implémenté par la bibliothèque Stable-Baselines3. Principales raisons de choisir PPO :
- Forte stabilité : limitez la portée des mises à jour de stratégie via le mécanisme Clip pour éviter les plantages de performances causés par une seule mise à jour trop volumineuse.
- Hyperparamètre robuste : la convergence peut être obtenue sans un grand nombre d’ajustements de paramètres, adaptée à la mise en œuvre du projet
- Prend en charge les espaces mixtes continus/discrets : bien que ce projet discrétise les actions, le cadre de PPO prend naturellement en charge une expansion de l’espace d’action plus complexe.
La fonction objective du PPO est :
Où
3.2 Structure du réseau
Le réseau de politiques utilise MlpPolicy (perceptron multicouche) :
- Couche de fonctionnalités partagée : deux couches de 128 unités entièrement connectées + activation ReLU
- En-tête de stratégie : génère la probabilité logarithmique d’une action discrète en 3 dimensions
- En-tête de valeur : estimation de la valeur de l’état de sortie
Hyperparamètres d’entraînement :| Paramètre | Valeur | |------|-----| | Taux d’apprentissage | 3e-4 | | GAE λ | 0,95 | | Facteur d’actualisation γ | 0,99 | | Nombre de pas par tour n_steps | 2048 | | taille du lot | 64 | | Coefficient d’entropie ent_coef | 0,01 |
4. Espace d’action et espace d’observation
4.1 Espace d’action (discret tridimensionnel)
| actions | valeur | comportement |
|---|---|---|
| Garder la voie | 0 | Conduire à vitesse constante dans la voie actuelle |
| Changer de voie à gauche | 1 | Initier un changement de voie vers la voie de gauche |
| Changer de voie vers la droite | 2 | Initier un changement de voie vers la voie de droite |
4.2 Espace d’observation (vecteur continu à 14 dimensions)
Le vecteur d’observation contient trois types d’informations :
Statut du véhicule principal (3D)
- Vitesse longitudinale
(normalisée) - Vitesse latérale
(normalisée) - Vitesse de croisière cible (normalisée, TARGET_SPEED = 50 km/h)
Perception environnante du véhicule (10 dimensions) Grâce à une configuration de capteur à 5 canaux, chaque canal renvoie « distance du véhicule le plus proche » + « vitesse relative » :
[左后] [左前]
↑
[后] ←—— [主车] ——→ [前]
↓
[右后] [右前]Informations routières (1D)
can_l: indique si la voie de gauche peut être modifiée (booléen)can_r: indique si la voie de droite peut être modifiée (booléen)st_code: état de refroidissement changeant de voie
5. Conception de la fonction de récompense
La fonction de récompense est la principale force motrice de l’apprentissage politique. Ce projet adopte une conception mixte de récompenses denses + incitations clairsemées :
5.1 Récompenses pour chaque composant
Bonus de vitesse (r_speed)
Lorsque vous atteignez la vitesse cible de 50 km/h, la récompense est de 1,0 ; à des vitesses inférieures, la récompense est moindre.
Pénalité pour embouteillage
Il s’agit de la principale force motrice qui pousse l’agent à changer activement de voie : des points continueront d’être déduits s’il est coincé derrière un véhicule plus lent.Récompense pour un changement de voie réussi
Un changement de voie est considéré comme réussi si et seulement si : un changement de voie est détecté dans les 35 étapes suivant la fin du refroidissement par changement de voie. Des récompenses élevées établissent une forte association « voie du changement → réussite ».
Pénalité de sécurité
Les collisions sont des lignes à haute tension et ne sont en aucun cas acceptables.
5.2 Analyse du signal de récompense
Pourquoi est-il conçu de cette façon ?
La pénalité embouteillage est fixée à pas trop lourde (-0,5) car si elle est trop lourde, l’agent « préférera s’écraser plutôt que de changer de voie » ; et la pénalité de collision est fixée à extrêmement lourde (-50) car la sécurité doit primer sur tout le reste. Grâce à une combinaison pondérée à plusieurs composants, la stratégie apprend enfin à changer activement de voie pour éviter les embouteillages dans un souci de sécurité.
6. Résultats et analyse de la formation
6.1 Configuration de la formation
- Carte : CARLA Town06 (route urbaine, multivoies bidirectionnelles)
- Pas de simulation : 0,1 seconde
- Nombre cible d’étapes de formation : 1 million d’étapes (1 million d’étapes)
- Device : Entraînement CPU (l’accélération GPU bénéficie principalement du parallélisme de la simulation physique)
- CHECKPOINT SAVE : enregistrez toutes les 10 000 étapes
6.2 Courbe d’entraînement
Après 270 000 étapes de formation (correspondant à environ 7,5 heures), l’agent a démontré des capacités évidentes de changement de voie :
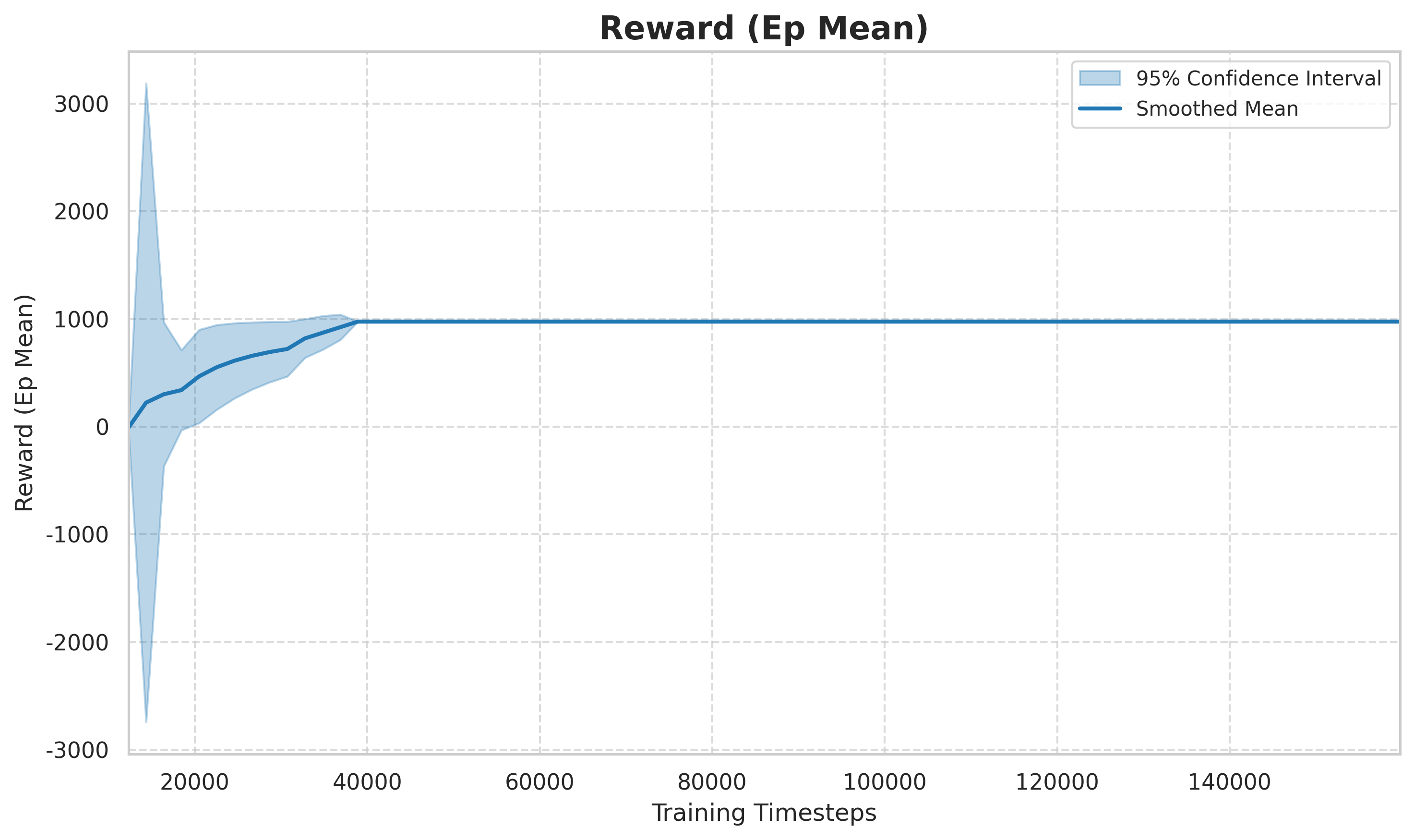
Figure : La récompense moyenne par épisode (moyenne de récompense par épisode) change avec le nombre d’étapes d’entraînement. Au début (étapes de 0 à 50 000), la récompense fluctue violemment et l’agent est dans la phase d’exploration aléatoire ; au stade intermédiaire (étapes de 50 000 à 150 000), la récompense augmente rapidement et la stratégie apprend progressivement à changer de voie pour obtenir des récompenses de vitesse plus élevée ; au stade ultérieur (plus de 150 000 étapes), elle a tendance à converger et la stratégie est proche de la solution sous-optimale.
6.3 Perte de valeur et perte de stratégie
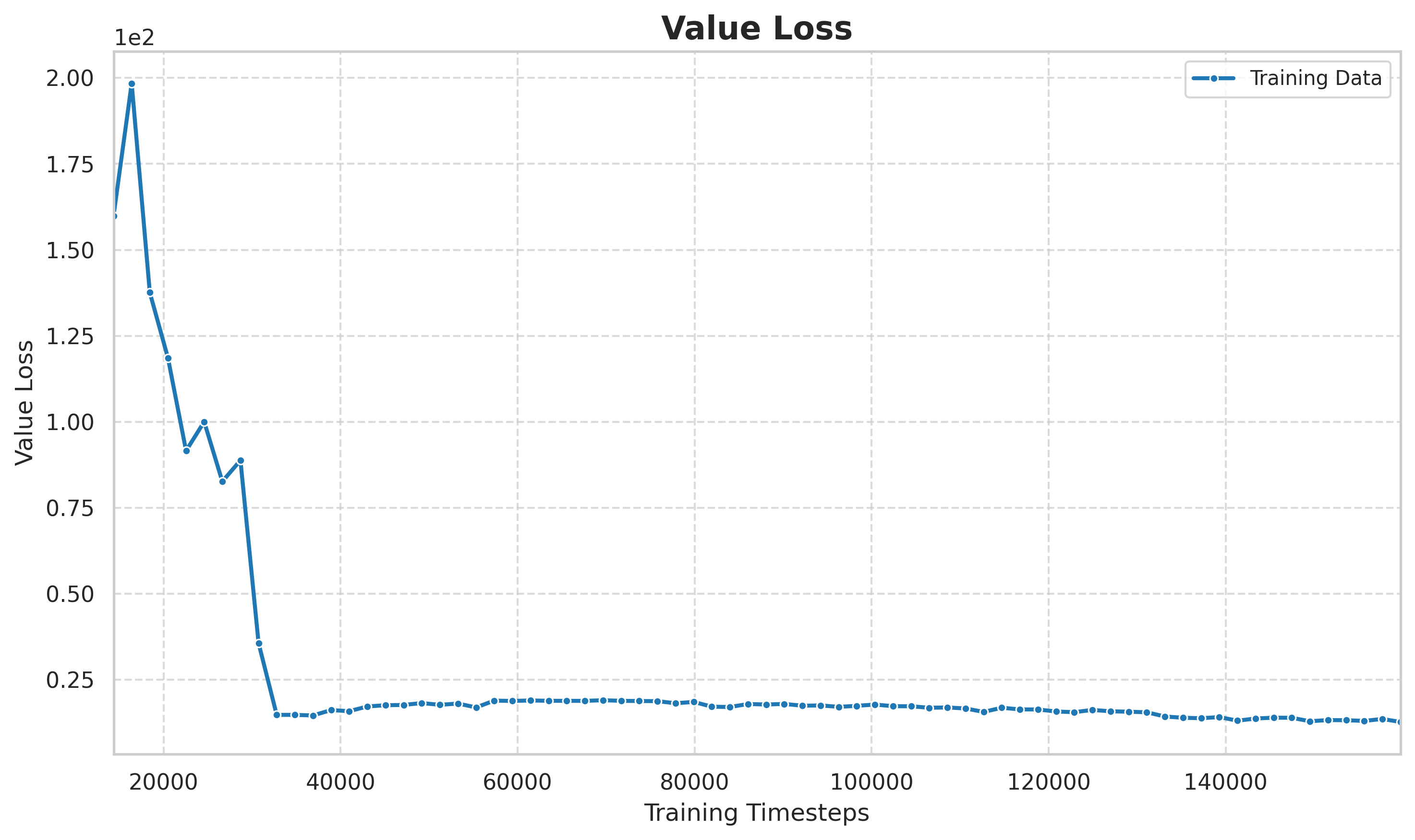 > Figure : La perte de valeur évolue avec le nombre d’étapes de formation. La perte initiale est élevée et le réseau de valeur apprend encore à estimer la valeur de l’état ; la perte aux stades intermédiaire et ultérieur se stabilise à un niveau faible, ce qui indique que l’estimation de la valeur a tendance à être précise, fournissant ainsi une base de référence fiable pour la fonction d’avantage.
> Figure : La perte de valeur évolue avec le nombre d’étapes de formation. La perte initiale est élevée et le réseau de valeur apprend encore à estimer la valeur de l’état ; la perte aux stades intermédiaire et ultérieur se stabilise à un niveau faible, ce qui indique que l’estimation de la valeur a tendance à être précise, fournissant ainsi une base de référence fiable pour la fonction d’avantage.
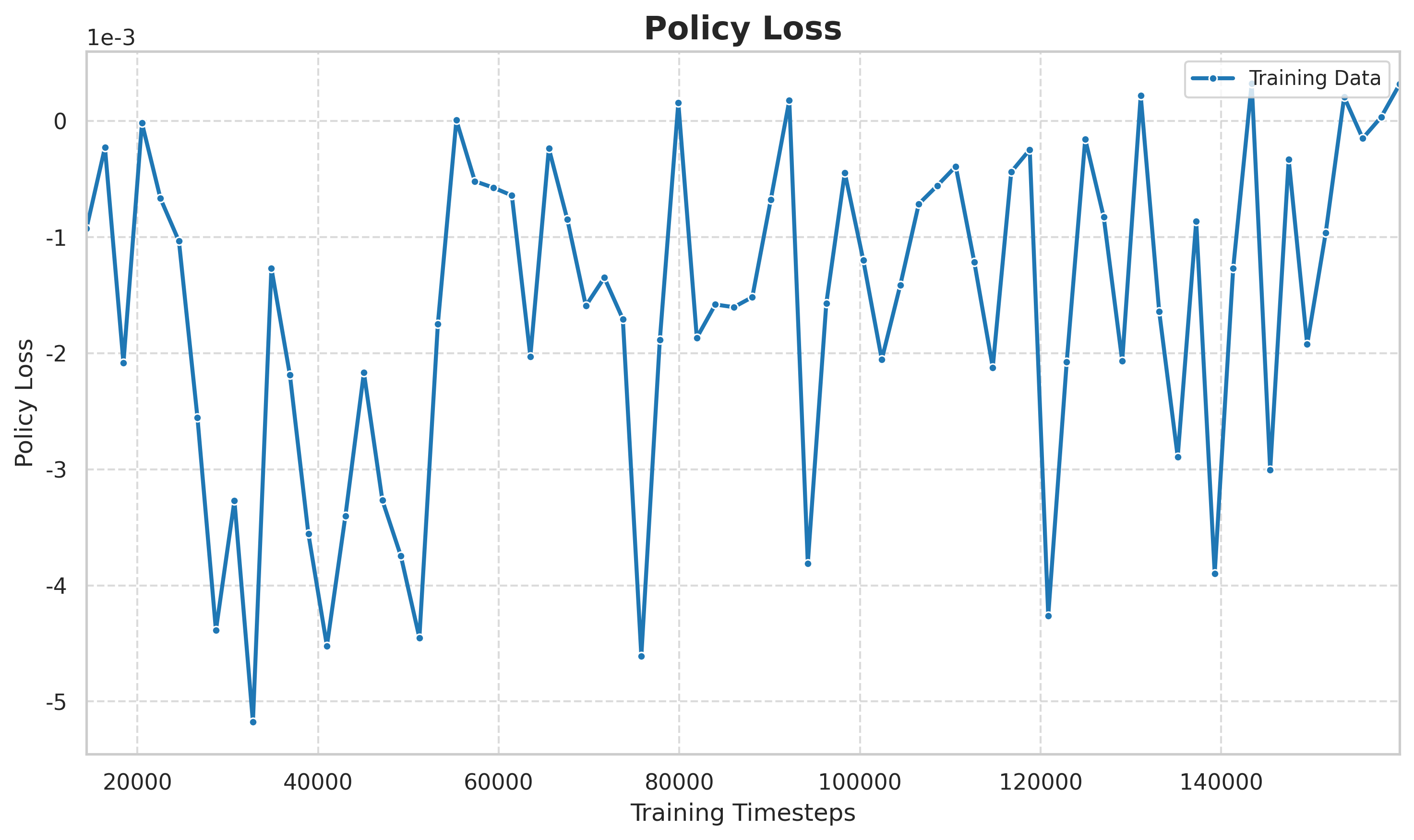
Graphique : Courbe de perte des polices d’assurance. La perte de stratégie de PPO reflète directement l’orientation et l’ampleur de la mise à jour de la stratégie, et on peut voir que la stratégie est ajustée dynamiquement entre l’exploration et l’exploitation.
6.4 Analyse de comparaison de vitesse
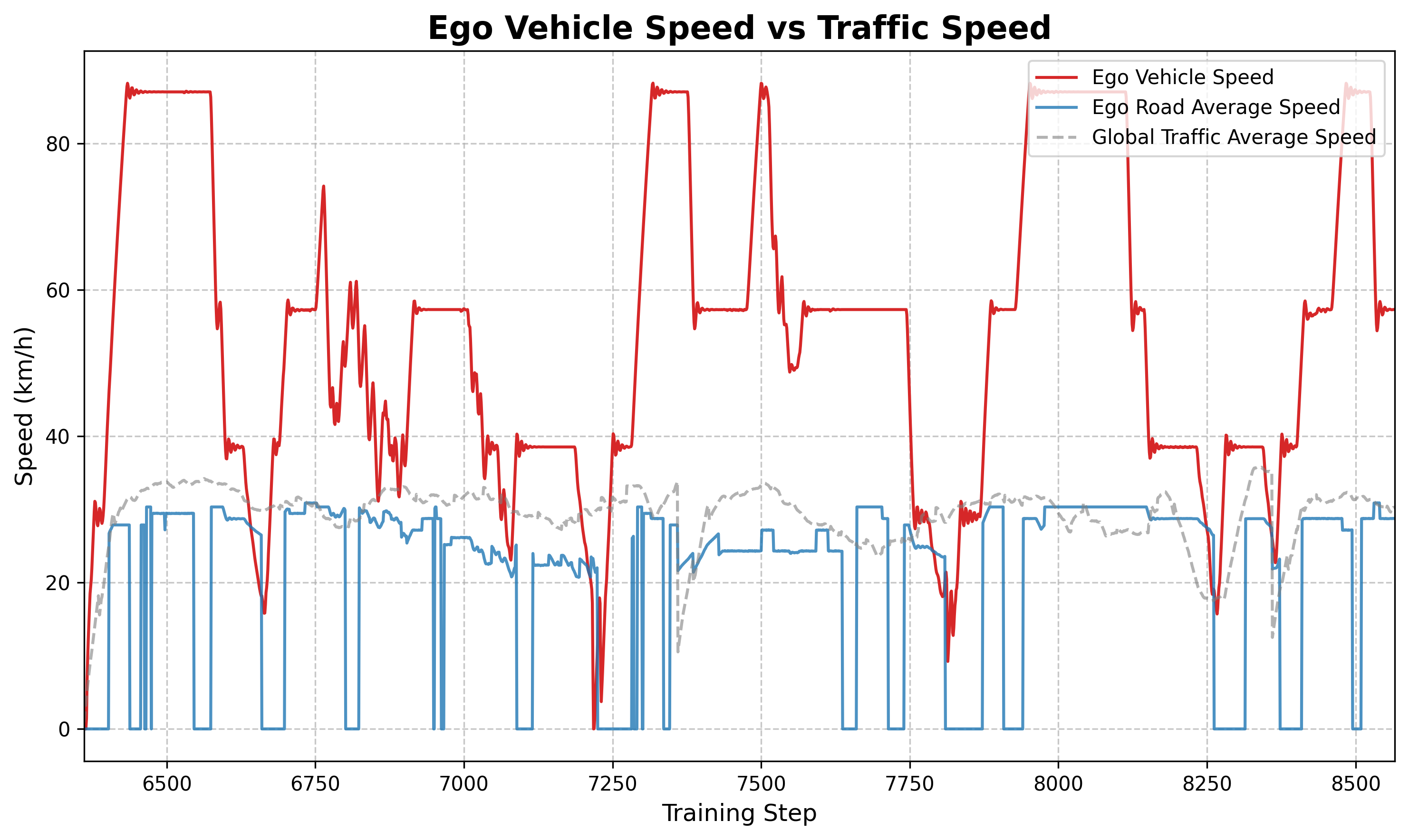
Figure : Comparaison de la vitesse du véhicule principal (orange) par rapport à la vitesse moyenne sur route (bleu). On peut observer que la vitesse globale du véhicule principal est supérieure à la vitesse moyenne du trafic, ce qui indique que la stratégie a appris à trouver activement des voies à grande vitesse ou à éliminer les embouteillages à basse vitesse.
6.5 Analyse de la fréquence des changements de voie
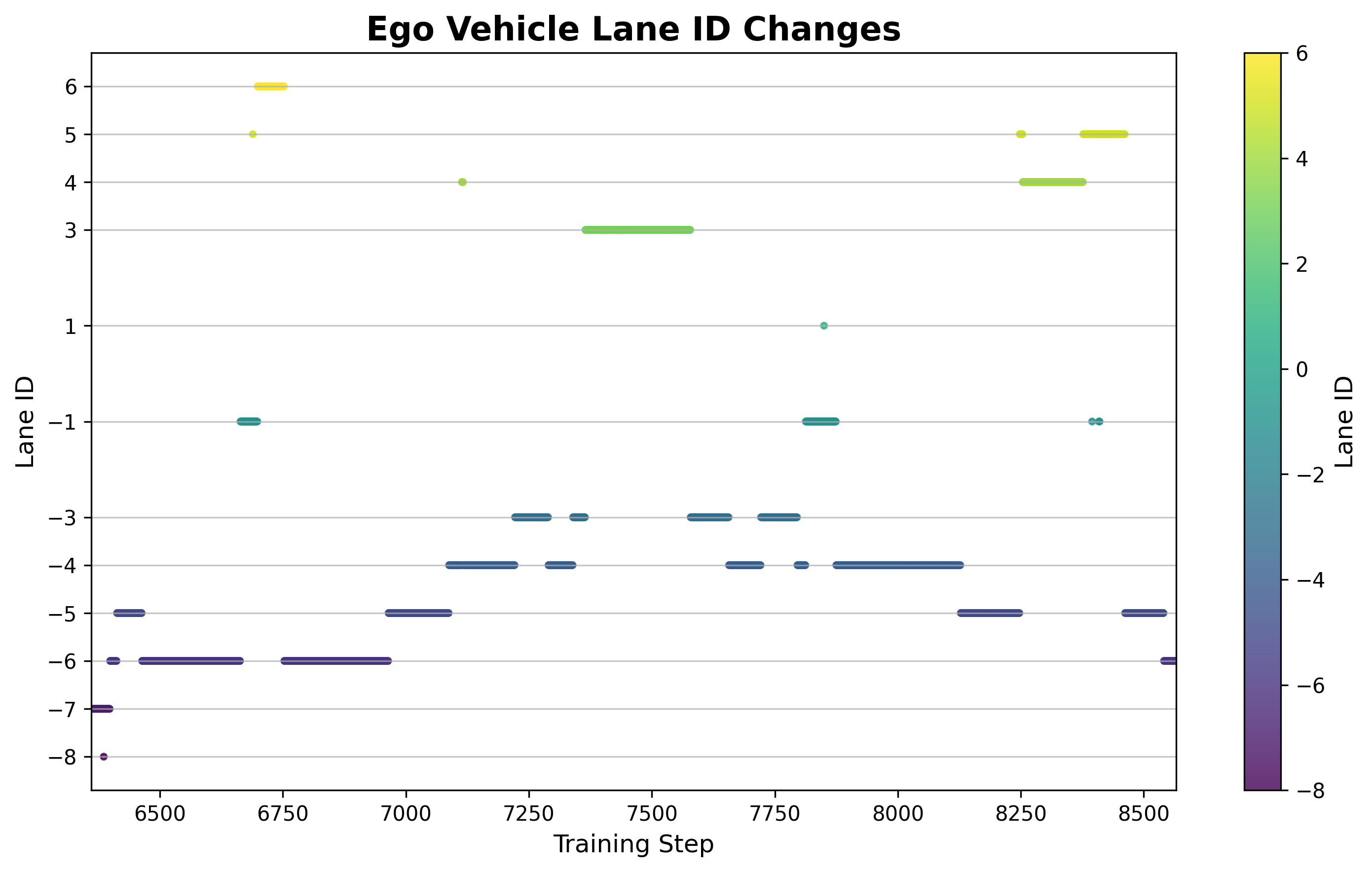
Figure : Evolution du nombre cumulé de changements de voie au cours de l’entraînement. Au début, les changements de voie étaient fréquents mais inefficaces (un grand nombre de changements de voie échoués). Au milieu et à la fin, les changements de voie ont été réduits mais le taux de réussite a été considérablement amélioré. La stratégie a appris à changer de voie lorsque cela était nécessaire au lieu de changer de voie aveuglément.
6.6 Points de contrôle enregistrés
Le projet enregistre 30 points de contrôle dans le répertoire checkpoints/, couvrant le processus de formation complet de 10 000 étapes à 270 000 étapes :
ppo_carla_autodrive_10006_steps.zip
ppo_carla_autodrive_20253_steps.zip
ppo_carla_autodrive_30253_steps.zip
...
ppo_carla_autodrive_270489_steps.zipChaque étape du point de contrôle peut être utilisée pour la récupération après interruption et l’expérience de comparaison de stratégies.
7. Détails d’implémentation du code clé
7.1 BridgeHelper : conversion de coordonnées
CARLA utilise un système de coordonnées pour gauchers (X avant, Y à droite, Z vers le haut), SUMO utilise un système de coordonnées pour droitiers et les deux axes sont opposés. BridgeHelper implémente cette conversion :
# 位置转换:SUMO → CARLA
carla_location = carla.Location(
x=sumo_x,
y=-sumo_y, # Y 轴取反
z=0.5
)
# 朝向角转换
carla_rotation = carla.Rotation(
pitch=0,
yaw=math.degrees(-sumo_angle), # 角度取反
roll=0
)7.2 Détection et nettoyage des interblocages
Les voitures en arrière-plan dans SUMO peuvent être bloquées dans une impasse en raison de feux rouges, d’embouteillages, etc. Ce projet implémente une détection intelligente des impasses :
def _check_and_remove_deadlock(self, vehicle_id):
speed = traci.vehicle.getSpeed(vehicle_id)
wait_time = traci.vehicle.getAccumulatedWaitingTime(vehicle_id)
if speed < 0.1:
if self._is_at_red_light(vehicle_id) and wait_time > 120:
traci.vehicle.remove(vehicle_id) # 红灯等待超时,移除
elif wait_time > 10:
traci.vehicle.remove(vehicle_id) # 非红灯死锁,快速清理7.3 Rappel personnalisé : TrafficLoggerCallbackPendant le processus de formation, les données de trafic sont automatiquement enregistrées au format CSV pour une analyse ultérieure :
class TrafficLoggerCallback(BaseCallback):
def _on_step(self) -> bool:
infos = self.locals["infos"][0]
self.writer.writerow([
self.num_timesteps,
infos.get('ego_speed_kmh', 0.0),
infos.get('average_speed', 0.0),
infos.get('ego_road_avg_speed', 0.0),
infos.get('current_lane_id', -1)
])
return True8. Aperçu de la structure du projet
carlaSumoRL/
├── assets/ # SUMO 地图配置、Town06 路网
│ ├── Town06.rou.xml # 交通流生成配置
│ ├── Town06.net.xml # SUMO 路网定义
│ ├── town06.sumocfg # SUMO 仿真配置文件
│ └── *.png # 可视化结果图
├── core/ # 核心仿真逻辑
│ ├── bridge_helper.py # 坐标系转换(368行)
│ ├── carla_simulation.py # CARLA 仿真控制(186行)
│ ├── sumo_simulation.py # SUMO 仿真控制(517行)
│ └── constants.py # 常量定义
├── envs/
│ └── carla_sumo_env.py # Gym 环境定义(469行)
├── checkpoints/ # 30个训练检查点
├── ppo_carla_tensorboard/ # TensorBoard 日志
├── train_ppo.py # 训练入口
├── test_ppo.py # 测试入口
├── plot_training_curve.py # 训练曲线可视化
├── plot_metrics.py # 交通数据分析
└── traffic_log.csv # 实时交通数据日志9. Limites et travaux futurs
Limites actuelles
- Espace d’observation limité : seul un capteur de rayons à 5 canaux est utilisé, l’entrée visuelle n’est pas utilisée et les informations sensorielles sont insuffisantes dans les scènes à grande vitesse.
- Scénario de véhicule à maître unique : la collaboration multi-agents n’est pas encore prise en charge et le jeu interactif de plusieurs véhicules changeant de voie en même temps n’a pas été modélisé.
- Le comportement du véhicule SUMO est simple : la voiture d’arrière-plan utilise le modèle de suivi de voiture IDM par défaut et n’a pas la différenciation des styles de conduite agressifs/conservateurs.
- La décision de changement de voie dépend du temps de refroidissement : Le changement de voie en conduite réelle nécessite une coordination en plusieurs étapes de la perception-décision-exécution, et le modèle actuel a été considérablement simplifié.
Orientations futures
- Présentation de la saisie d’image : utilisez CNN ou Vision Transformer pour traiter les données des caméras du véhicule afin de mettre en œuvre une stratégie de vision de bout en bout
- Extension multi-agents : introduisez plusieurs véhicules principaux autonomes pour étudier des jeux interactifs et des scénarios de confrontation
- Cours d’apprentissage : Passer progressivement de scénarios simples (routes vides) à des scénarios complexes (trafic à haute densité, fusion de rampes)
- Real Road Verification : migrez la stratégie formée vers le framework Carla_ROS et vérifiez-la sur un véhicule réel ou une plateforme hardware-in-the-loop
10. Résumé
Ce projet met entièrement en œuvre un cadre de formation au changement de voie de conduite autonome simulation collaborative CARLA-SUMO + apprentissage par renforcement PPO. Grâce à la collaboration de deux simulateurs, il garantit non seulement l’authenticité de la dynamique principale du véhicule, mais garantit également la diversité et le défi du flux de trafic en arrière-plan.
La taille du code du projet est d’environ 1 540 lignes, avec une structure claire, couvrant l’ensemble du processus de formation-test-visualisation, et 30 points de contrôle ont été enregistrés pour la reproduction et le développement secondaire. Si vous êtes intéressé par la planification des décisions en matière de conduite autonome et par l’application de l’apprentissage par renforcement dans des scénarios de circulation, ce cadre est un bon point de départ.
Adresse du projet : /home/tartlab/project/outwork/carlaSumoRL/
Auteur : Tarte Kagura | 2026-04-15