#CARLA-SUMO 協調シミュレーション強化学習フレームワーク: 自動運転車に積極的な車線変更を学習させる
1. はじめに: なぜ協調シミュレーションが必要なのでしょうか?
自動運転の車線変更戦略のトレーニングは根本的な矛盾に直面しています。
- CARLA は、物理レベルまで正確な、エンジン応答、タイヤ摩擦、サスペンション ダイナミクスなど、忠実度の高い車両ダイナミクス シミュレーションを提供します。ただし、デフォルトではメイン車両のみが自律走行しており、バックグラウンドのトラフィックは手動で設定する必要があります。
- SUMO は大規模な交通流シミュレーションに優れています。数百、数千台のバックグラウンド車両を簡単に生成して、実際の都市交通の渋滞、追従、車線変更の動作をシミュレートできます。しかし、SUMO の車両モデルは巨視的であり、動的な詳細が欠けています。
**どちらか一方だけでは十分ではありません。 **
CARLA のみを使用する場合、バックグラウンド トラフィックはまばらで、車線変更の決定はそれほど困難ではありません。 SUMO のみを使用すると、車両の挙動が「規則的」すぎるため、真の動的応答を学習することができません。
その結果、協調シミュレーションが最適なソリューションとなりました。CARLA が主要車両のダイナミクスを管理し、SUMO がバックグラウンドのトラフィック フローを管理し、TraCI プロトコルを通じてステータスをリアルタイムで同期します。これがこのプロジェクトの核となるデザインです。
2. システム アーキテクチャ: デュアル エミュレータはどのように連携しますか?
2.1 並列アーキテクチャ
CARLA と SUMO は 2 つの独立したプロセスとして実行され、Python インターフェイス (CARLA Python API + TraCI) を通じて通信します。システム全体のデータの流れは以下の通りです。
┌─────────────┐ TraCI ┌─────────────┐
│ SUMO │ ←────────────→ │ CARLA │
│ (交通流) │ 状态同步 │ (动力学) │
└─────────────┘ └─────────────┘
↑ ↑
│ │
└─────── 主车状态双向同步 ───────┘
(BridgeHelper)- SUMO は、背景車両の生成、移動、車線変更、および交通規則レベルでの意思決定を担当します。
- CARLA は、Ego Vehicle の正確な動的応答、つまり加速、ブレーキ、ステアリングの実際の物理的効果を担当します。
- BridgeHelper は 2 つの世界の「変換者」であり、座標系の変換 (左手の座標系 ↔ 右手の座標系)、位置の変換、向きの角度の反転を担当します。
2.2 時刻同期の仕組み
協調シミュレーションの中核は、厳密にシーケンシャルな同期関数 _sync_world です。
def _sync_world(self):
# 1. 推进 SUMO,获取所有交通参与者状态
sumo_sim.tick()
# 2. SUMO → CARLA:同步背景车辆位置
self._sync_sumo_to_carla()
# 3. 推进 CARLA,应用主车控制指令
carla_sim.tick()
# 4. CARLA → SUMO:同步主车位置回 SUMO(幽灵车)
self._sync_carla_to_sumo()各シミュレーション ステップは 0.1 秒 (STEP_LENGTH = 0.1) で、精度と効率のバランスが取れています。
2.3 主な車両制御機構マスター車両は、CARLA の Traffic Manager (TM) を介して引き継ぎます。 TM はいくつかの重要なパラメータを設定します。
set_synchronous_mode(True)— TM がシミュレーション ステップと同期していることを保証する同期モード- 自動車線変更を無効にする - 車線変更の決定は強化学習ポリシーによって 100% 制御されます -車間距離 3.0 メートル - 安全な車間距離を維持してください
- 信号無視 - 意思決定シナリオの簡素化
ポリシーが車線変更アクションを出力する場合、「force_lane_change」を通じて強制車線変更コマンドを送信し、40 ステップ (約 4 秒) の車線変更冷却時間を設定します。
3. 強化学習アルゴリズム: PPO
3.1 PPO を選択する理由は何ですか?
このプロジェクトは、Stable-Baselines3 ライブラリによって実装された 近接ポリシー最適化 (PPO) アルゴリズムを使用します。 PPO を選択する主な理由:
- 強力な安定性: 1 つの大規模な更新によって引き起こされるパフォーマンスのクラッシュを回避するために、クリップ メカニズムを通じてポリシー更新の範囲を制限します。
- 堅牢なハイパーパラメータ: 多数のパラメータ調整を行わずに収束を達成できるため、プロジェクトの実装に適しています
- 連続/離散混合空間のサポート: このプロジェクトはアクションを離散化しますが、PPO のフレームワークはより複雑なアクション空間の拡張を自然にサポートします。
PPO の目的関数は次のとおりです。
ここで、
3.2 ネットワーク構造
ポリシー ネットワークは MlpPolicy (多層パーセプトロン) を使用します。
- 共有フィーチャ レイヤー: 2 つの 128 ユニット完全接続レイヤー + ReLU アクティベーション
- ポリシーヘッダー: 3次元の離散アクションの対数確率を出力します。
- 値ヘッダー: 出力状態値推定値
トレーニングのハイパーパラメータ:|パラメータ |値 | |------|-----| |学習率 | 3e-4 | | GAE λ | 0.95 | |割引係数 γ | 0.99 | |ラウンドごとのステップ数 n_steps | 2048年 | |バッチサイズ | 64 | |エントロピー係数 ent_coef | 0.01 |
4. 行動空間と観察空間
4.1 アクション空間 (3 次元離散)
| アクション | 値 | 行動 |
|---|---|---|
| 車線を維持 | 0 | 現在の車線を一定の速度で走行します |
| 左に車線変更 | 1 | 左車線への車線変更を開始する |
| 右に車線変更 | 2 | 右車線への車線変更を開始する |
4.2 観測空間(14次元連続ベクトル)
観測ベクトルには 3 種類の情報が含まれています。
主な車両ステータス(3D)
- 縦速度
(正規化) - 横速度
(正規化) - 目標巡航速度 (正規化、TARGET_SPEED = 50 km/h)
周囲車両知覚 (10 次元) 5 チャンネルのセンサー構成を使用して、各チャンネルは「最も近い車両の距離」+「相対速度」を返します。
[左后] [左前]
↑
[后] ←—— [主车] ——→ [前]
↓
[右后] [右前]道路情報(1D)
can_l: 左車線を変更できるかどうか (ブール値)can_r: 右車線を変更できるかどうか (ブール値)st_code: 車線変更冷却ステータス
5. 報酬関数の設計
報酬関数は、ポリシー学習の中核となる原動力です。このプロジェクトは、密な報酬 + 希薄なインセンティブ の混合設計を採用しています。
5.1 各コンポーネントの報酬
スピードボーナス (r_speed)
目標速度 50 km/h に到達すると、報酬は 1.0 になります。低速では報酬は小さくなります。
渋滞ペナルティ
これは、エージェントが積極的に車線変更するよう駆り立てる中心的な原動力です。遅い車両の後ろに閉じ込められた場合、ポイントは減点され続けます。車線変更成功時の報酬
車線変更は、車線変更冷却が完了してから 35 ステップ以内に車線変更が検出された場合にのみ成功したとみなされます。高額な報酬は、「車線変更→成功」という強い結びつきを確立します。
セーフティペナルティ
衝突は高圧線であり、いかなる状況でも容認できません。
5.2 報酬シグナル分析
なぜこのように設計されているのでしょうか?
渋滞ペナルティは、重すぎない (-0.5) に設定されています。これは、重すぎると、エージェントが「車線を変更するよりも衝突することになる」ためです。安全性が他のすべてを優先する必要があるため、衝突ペナルティは 非常に重い (-50) に設定されます。複数のコンポーネントの重み付けを組み合わせることにより、この戦略は最終的に、安全を前提として渋滞を回避するために積極的に車線を変更することを学習します。
6. トレーニング結果と分析
6.1 トレーニング構成
- 地図: CARLA Town06 (都市道路、双方向多車線)
- シミュレーションステップ: 0.1秒
- 目標トレーニングステップ数:100万ステップ(1Mステップ)
- デバイス: CPU トレーニング (GPU アクセラレーションは主に物理シミュレーションの並列処理から恩恵を受けます)
- チェックポイント保存: 10,000 歩ごとに保存します
6.2 トレーニングカーブ
270,000 ステップのトレーニング (約 7.5 時間に相当) の後、エージェントは明確な車線変更能力を実証しました。
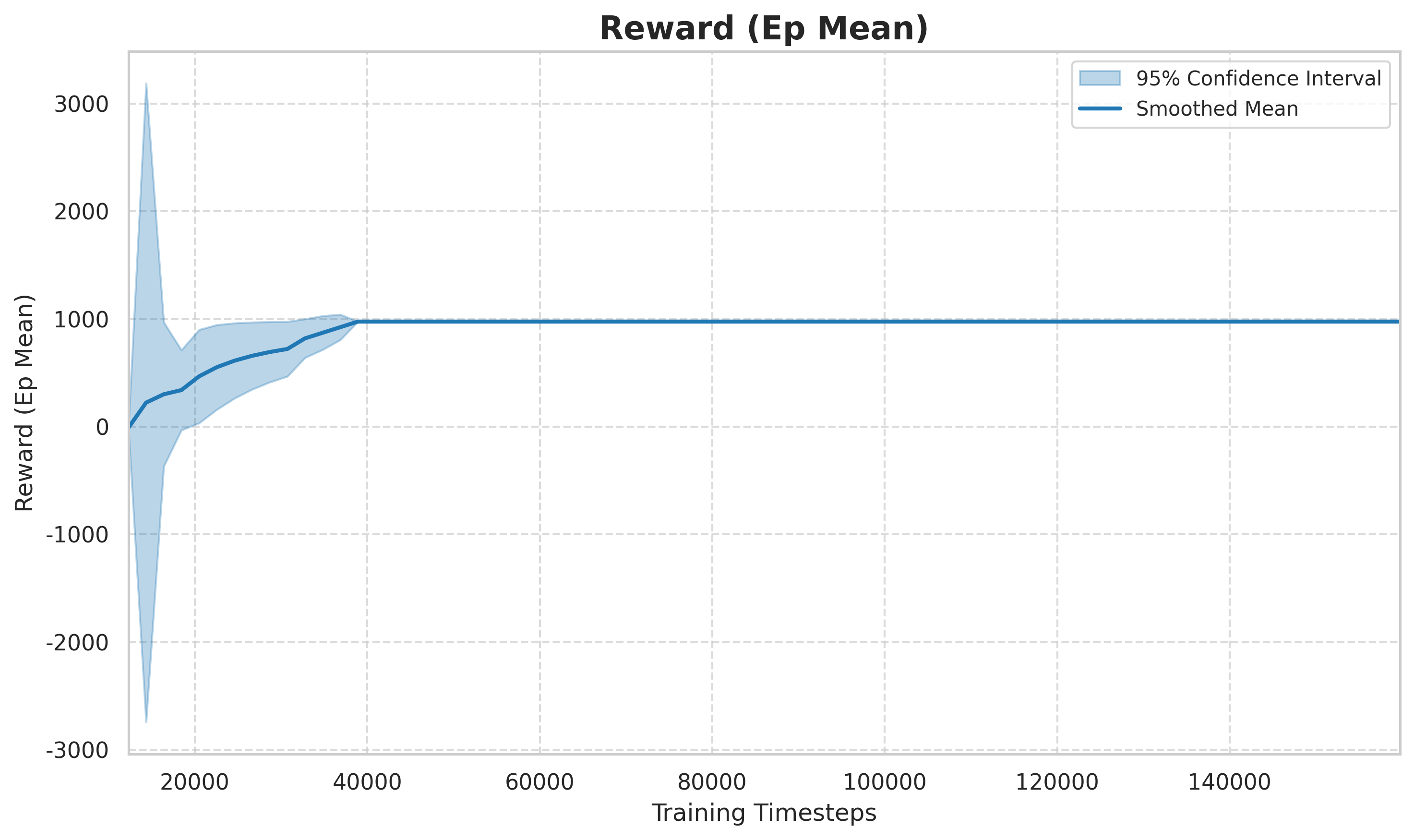
図: エピソードごとの平均報酬 (エピソード報酬の平均) は、トレーニング ステップの数に応じて変化します。初期段階 (0 ~ 50k ステップ) では、報酬は激しく変動し、エージェントはランダムな探索段階にあります。中盤(50k〜150kステップ)では、報酬が急速に上昇し、戦略は徐々にレーンを変更してより高速な報酬を獲得することを学習します。後の段階 (150k+ ステップ) では収束する傾向があり、戦略は準最適解に近づきます。
6.3 価値の損失と戦略の損失
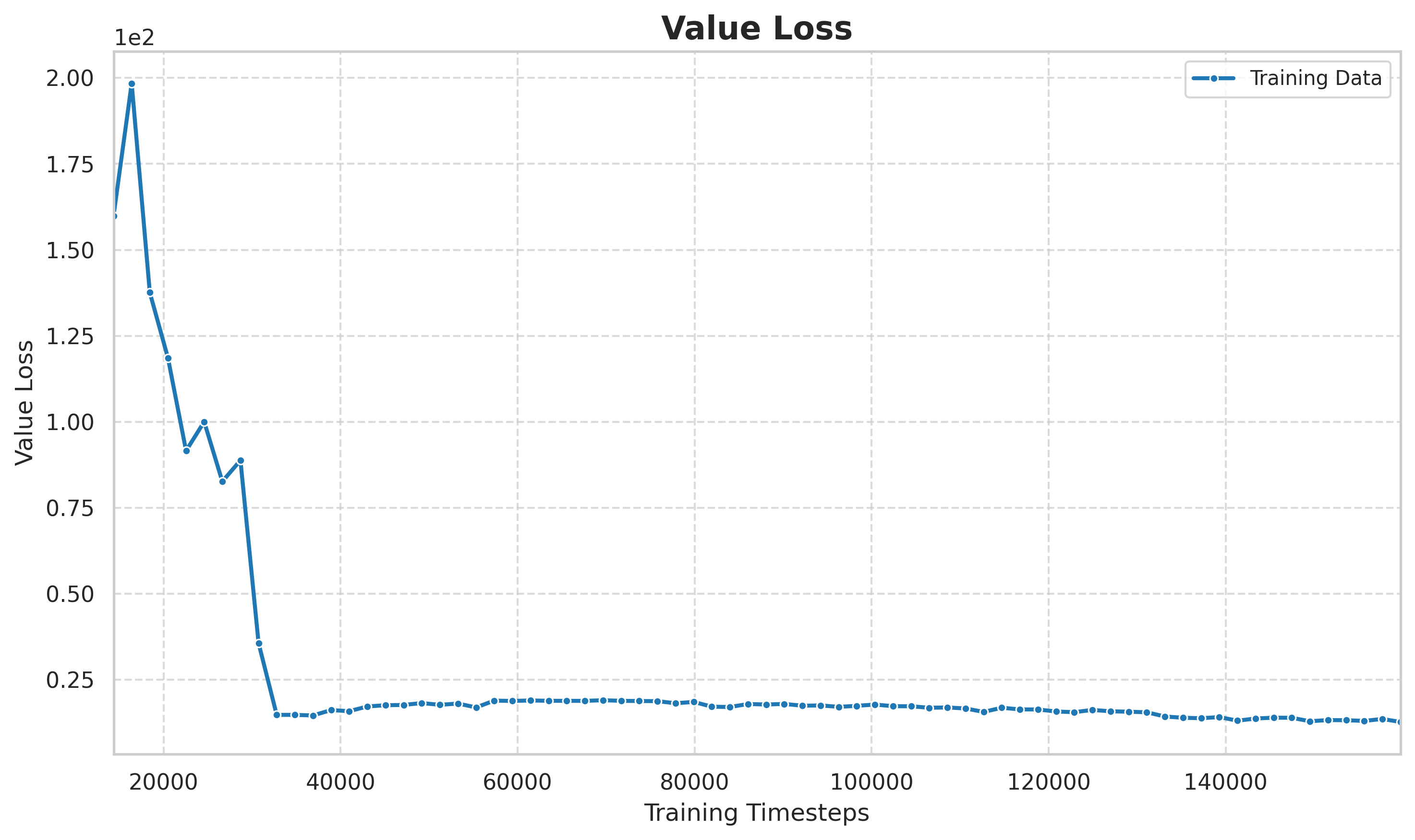 > 図: 値の損失はトレーニング ステップ数に応じて変化します。初期損失は高く、値ネットワークはまだ状態値の推定を学習中です。中期以降の損失は低いレベルで安定しており、値の推定が正確である傾向があり、アドバンテージ関数の信頼できるベースラインを提供していることを示しています。
> 図: 値の損失はトレーニング ステップ数に応じて変化します。初期損失は高く、値ネットワークはまだ状態値の推定を学習中です。中期以降の損失は低いレベルで安定しており、値の推定が正確である傾向があり、アドバンテージ関数の信頼できるベースラインを提供していることを示しています。
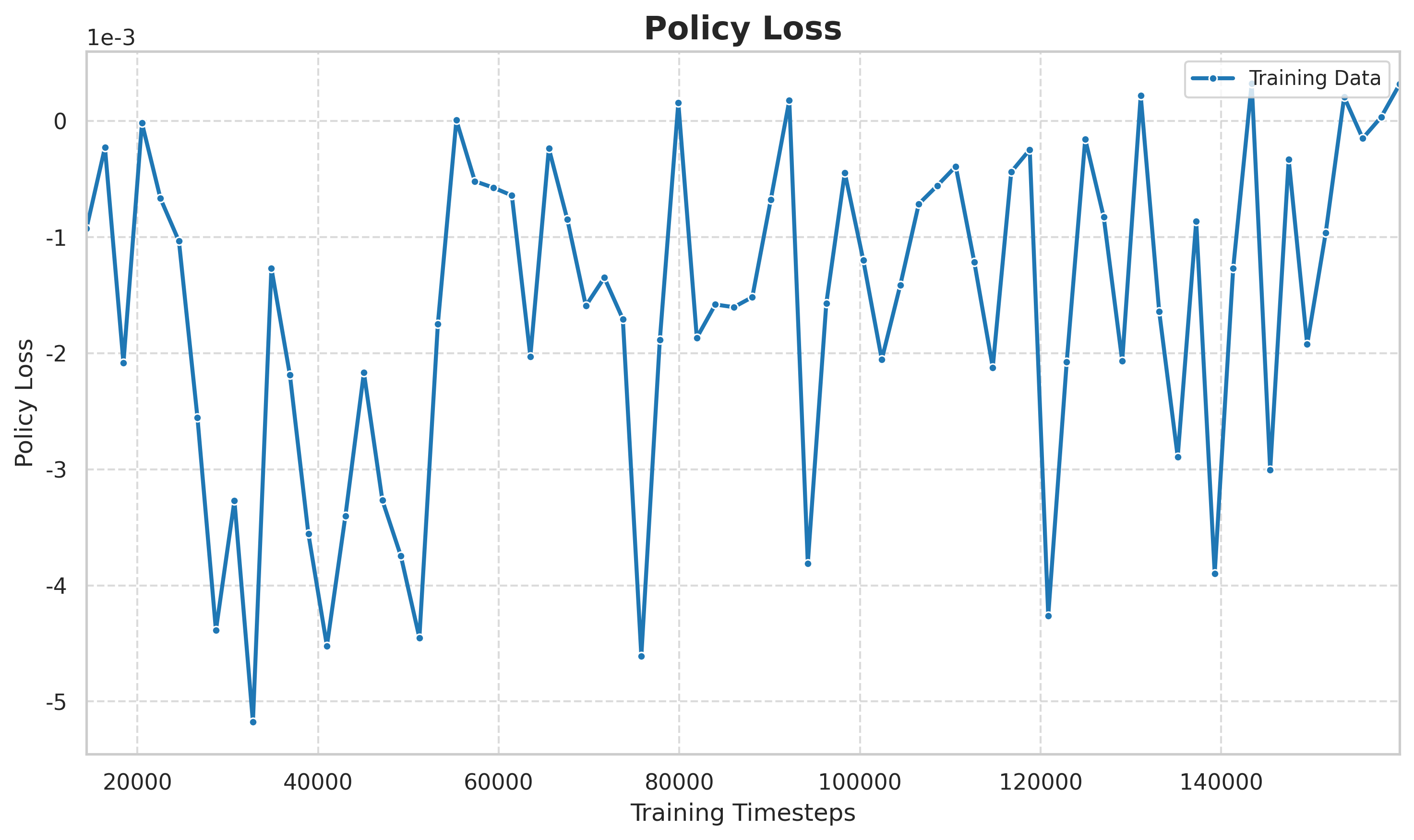
図: 保険損失曲線。 PPO の戦略損失は、戦略更新の方向と規模を直接反映しており、探索と活用の間で戦略が動的に調整されていることがわかります。
6.4 速度比較分析
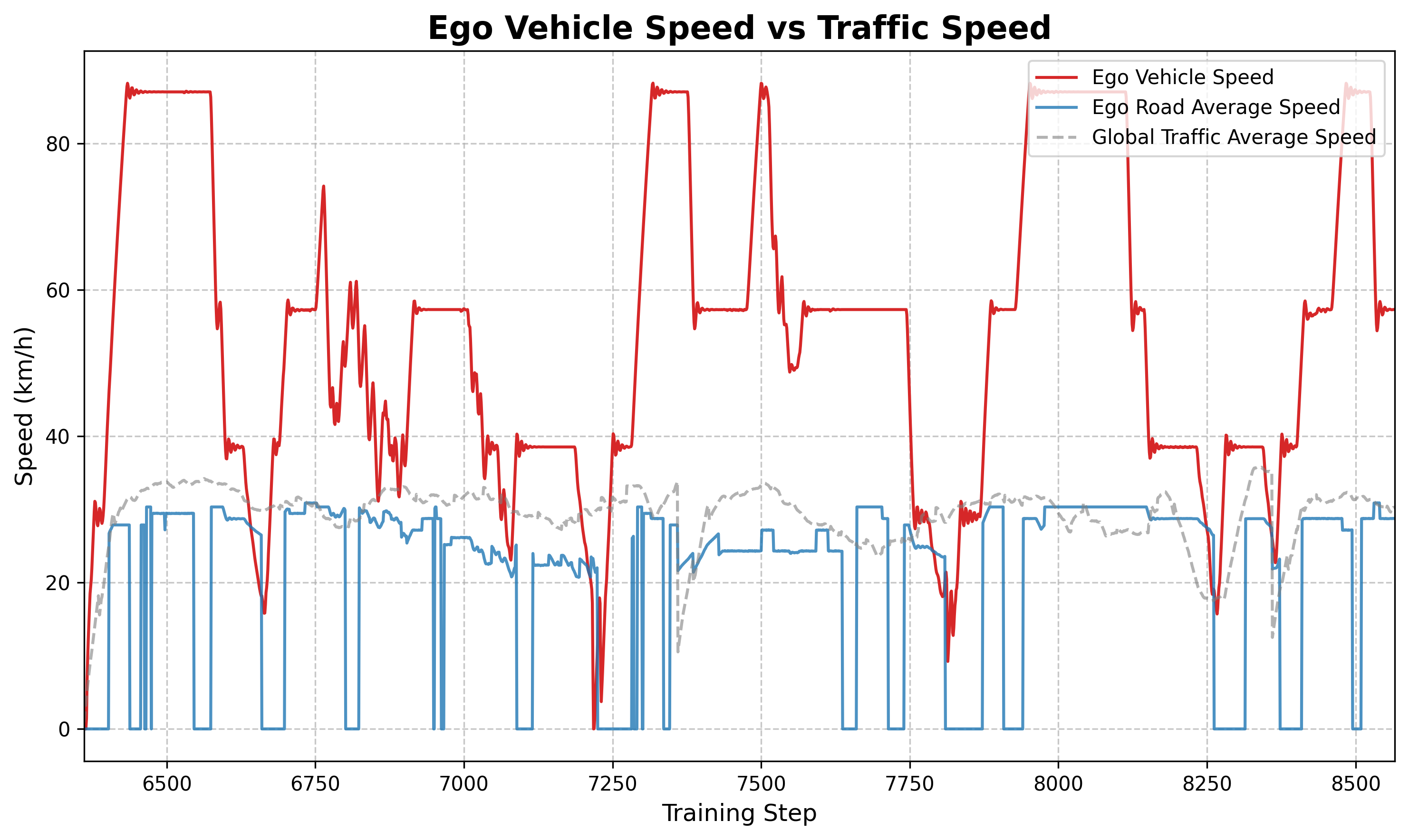
図: 主な車両速度 (オレンジ) と平均道路速度 (青) の比較。主要車両の全体速度が交通流の平均速度よりも高いことが観察でき、これは戦略が積極的に高速車線を見つけたり、低速の渋滞を解消したりすることを学習したことを示しています。
6.5 車線変更頻度分析
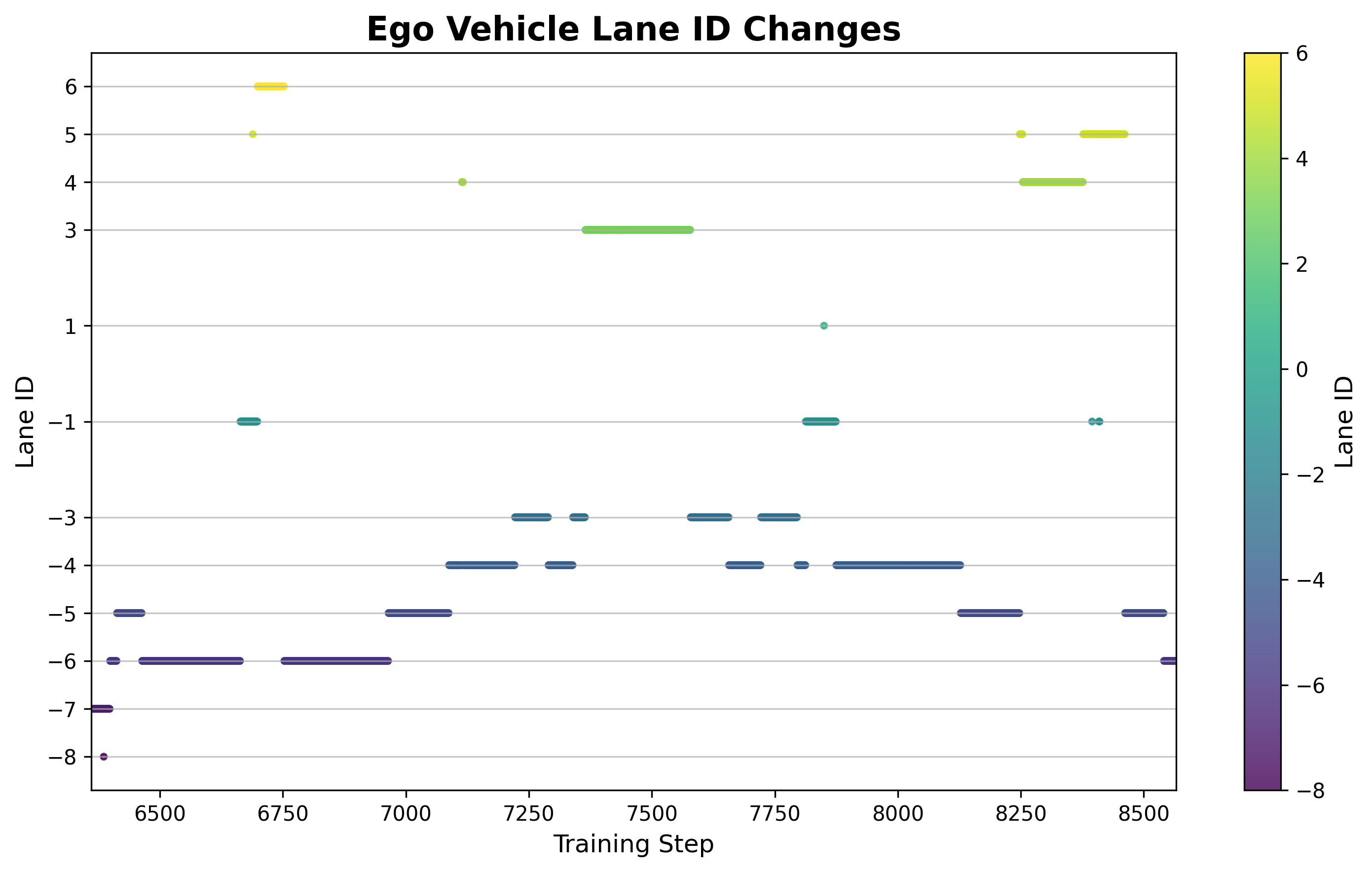
図: トレーニング中の累積車線変更回数の変化。初期段階では、車線変更は頻繁に行われていましたが、非効率的でした(車線変更の失敗が多数発生)。中後半ではレーンチェンジは減りましたが、成功率は大幅に向上しました。この戦略は、やみくもに車線を変更するのではなく、必要に応じて車線を変更することを学びました。
6.6 保存されたチェックポイント
このプロジェクトは、30 のチェックポイントを checkpoints/ ディレクトリに保存し、10,000 ステップから 270,000 ステップまでの完全なトレーニング プロセスをカバーします。
ppo_carla_autodrive_10006_steps.zip
ppo_carla_autodrive_20253_steps.zip
ppo_carla_autodrive_30253_steps.zip
...
ppo_carla_autodrive_270489_steps.zip各チェックポイントのステップは、中断回復および戦略比較実験に使用できます。
7. キーコード実装の詳細
7.1 BridgeHelper: 座標変換
CARLA は左手座標系 (X 前方、Y 右方、Z 上方) を使用し、SUMO は右手座標系を使用し、2 つの軸は逆になります。 BridgeHelper はこの変換を実装します。
# 位置转换:SUMO → CARLA
carla_location = carla.Location(
x=sumo_x,
y=-sumo_y, # Y 轴取反
z=0.5
)
# 朝向角转换
carla_rotation = carla.Rotation(
pitch=0,
yaw=math.degrees(-sumo_angle), # 角度取反
roll=0
)7.2 デッドロックの検出とクリーニング
SUMO の背景の車は、赤信号や渋滞などによりデッドロックに陥る可能性があります。このプロジェクトはインテリジェントなデッドロック検出を実装しています。
def _check_and_remove_deadlock(self, vehicle_id):
speed = traci.vehicle.getSpeed(vehicle_id)
wait_time = traci.vehicle.getAccumulatedWaitingTime(vehicle_id)
if speed < 0.1:
if self._is_at_red_light(vehicle_id) and wait_time > 120:
traci.vehicle.remove(vehicle_id) # 红灯等待超时,移除
elif wait_time > 10:
traci.vehicle.remove(vehicle_id) # 非红灯死锁,快速清理7.3 カスタム コールバック: TrafficLoggerCallbackトレーニング プロセス中に、トラフィック データはその後の分析のために CSV に自動的に記録されます。
class TrafficLoggerCallback(BaseCallback):
def _on_step(self) -> bool:
infos = self.locals["infos"][0]
self.writer.writerow([
self.num_timesteps,
infos.get('ego_speed_kmh', 0.0),
infos.get('average_speed', 0.0),
infos.get('ego_road_avg_speed', 0.0),
infos.get('current_lane_id', -1)
])
return True8. プロジェクト構造の概要
carlaSumoRL/
├── assets/ # SUMO 地图配置、Town06 路网
│ ├── Town06.rou.xml # 交通流生成配置
│ ├── Town06.net.xml # SUMO 路网定义
│ ├── town06.sumocfg # SUMO 仿真配置文件
│ └── *.png # 可视化结果图
├── core/ # 核心仿真逻辑
│ ├── bridge_helper.py # 坐标系转换(368行)
│ ├── carla_simulation.py # CARLA 仿真控制(186行)
│ ├── sumo_simulation.py # SUMO 仿真控制(517行)
│ └── constants.py # 常量定义
├── envs/
│ └── carla_sumo_env.py # Gym 环境定义(469行)
├── checkpoints/ # 30个训练检查点
├── ppo_carla_tensorboard/ # TensorBoard 日志
├── train_ppo.py # 训练入口
├── test_ppo.py # 测试入口
├── plot_training_curve.py # 训练曲线可视化
├── plot_metrics.py # 交通数据分析
└── traffic_log.csv # 实时交通数据日志9. 制限と今後の課題
現在の制限事項
- 限られた観察スペース: 5 チャンネルの光線センサーのみが使用され、視覚入力は使用されず、高速シーンでは感覚情報が不十分です。
- 単一マスター車両のシナリオ: マルチエージェントのコラボレーションはまだサポートされておらず、複数の車両が同時に車線変更するインタラクティブ ゲームはモデル化されていません。
- SUMO 車両の動作はシンプルです: 背景の車はデフォルトの IDM 車追従モデルを使用しており、積極的/保守的な運転スタイルの区別がありません。
- 車線変更の判断は冷却時間に依存: 実際の運転における車線変更には、知覚、判断、実行の多段階の調整が必要ですが、現在のモデルは大幅に簡素化されています。
今後の方向性
- 画像入力の紹介: CNN または Vision Transformer を使用して車両カメラ データを処理し、エンドツーエンドのビジョン戦略を実装します。
- マルチエージェントの拡張: インタラクティブなゲームや対立シナリオを研究するために、複数の自動運転主要車両を導入します。
- コース学習: 単純なシナリオ (空いている道路) から複雑なシナリオ (高密度の交通、ランプの合流) に徐々に移行します。
- 実際の道路検証: トレーニングされた戦略を Carla_ROS フレームワークに移行し、実際の車両またはハードウェアインザループ プラットフォームで検証します。
10. まとめ
このプロジェクトは、CARLA-SUMO 協調シミュレーション + PPO 強化学習 自動運転車線変更トレーニング フレームワークを完全に実装します。デュアル シミュレーターの連携により、主要な車両ダイナミクスの信頼性が保証されるだけでなく、バックグラウンドの交通の流れの多様性と課題も保証されます。
プロジェクトのコードサイズは約1540行で、トレーニング・テスト・可視化プロセス全体をカバーする明確な構造となっており、再現や二次開発用に30のチェックポイントが保存されています。自動運転の意思決定計画と交通シナリオにおける強化学習の適用に興味がある場合、このフレームワークは良い出発点になります。
プロジェクトアドレス: /home/tartlab/project/outwork/carlaSumoRL/
※著者:神楽タルト | 2026-04-15*