#CARLA-SUMO Co-simulation reinforcement learning framework: Let self-driving cars learn to actively change lanes
1. Introduction: Why is co-simulation needed?
Training autonomous driving lane changing strategies faces a fundamental contradiction:
- CARLA provides high-fidelity vehicle dynamics simulation - engine response, tire friction, suspension dynamics, accurate to the physical level. But by default, only the main vehicle is autonomous, and background traffic needs to be configured manually.
- SUMO is good at large-scale traffic flow simulation - it can easily generate hundreds or thousands of background cars to simulate the congestion, following and lane-changing behaviors of real urban traffic. But SUMO’s vehicle model is macroscopic and lacks dynamic details.
**Either one alone is not enough. **
If only CARLA is used, the background traffic is sparse and lane-changing decisions are less challenging. If you only use SUMO, the vehicle behavior is too “regular” and it is impossible to learn the true dynamic response.
As a result, Co-simulation became the optimal solution - CARLA manages the dynamics of the main vehicle, SUMO manages the background traffic flow, and synchronizes the status in real time through the TraCI protocol. This is the core design of this project.
2. System architecture: How do dual emulators collaborate?
2.1 Parallel architecture
CARLA and SUMO run as two independent processes and communicate through a Python interface (CARLA Python API + TraCI). The data flow of the entire system is as follows:
┌─────────────┐ TraCI ┌─────────────┐
│ SUMO │ ←────────────→ │ CARLA │
│ (交通流) │ 状态同步 │ (动力学) │
└─────────────┘ └─────────────┘
↑ ↑
│ │
└─────── 主车状态双向同步 ───────┘
(BridgeHelper)- SUMO is responsible for the generation, movement, lane changing of background vehicles, and decision-making at the traffic rules level.
- CARLA is responsible for the precise dynamic response of the Ego Vehicle - the actual physical effects of acceleration, braking, and steering.
- BridgeHelper is the “translator” of the two worlds, responsible for coordinate system conversion (left-hand coordinate system ↔ right-hand coordinate system), position translation, and orientation angle reversal.
2.2 Time synchronization mechanism
The core of co-simulation is a strictly sequential synchronization function _sync_world:
def _sync_world(self):
# 1. 推进 SUMO,获取所有交通参与者状态
sumo_sim.tick()
# 2. SUMO → CARLA:同步背景车辆位置
self._sync_sumo_to_carla()
# 3. 推进 CARLA,应用主车控制指令
carla_sim.tick()
# 4. CARLA → SUMO:同步主车位置回 SUMO(幽灵车)
self._sync_carla_to_sumo()Each simulation step is 0.1 seconds (STEP_LENGTH = 0.1), balancing accuracy and efficiency.
2.3 Main vehicle control mechanismThe master vehicle takes over via CARLA’s Traffic Manager (TM). TM configures several key parameters:
set_synchronous_mode(True)— synchronous mode to ensure that TM is synchronized with the simulation step- Disable automatic lane changing - lane changing decisions are 100% controlled by the reinforcement learning policy -Following distance 3.0 meters - maintain a safe following distance
- Ignore traffic lights - simplify decision-making scenarios
When the policy outputs a lane change action, send a forced lane change command through force_lane_change, and set a lane change cooling time of 40 steps (about 4 seconds).
3. Reinforcement learning algorithm: PPO
3.1 Why choose PPO?
This project uses the Proximal Policy Optimization (PPO) algorithm, implemented by the Stable-Baselines3 library. Core reasons for choosing PPO:
- Strong stability: Limit the scope of policy updates through the Clip mechanism to avoid performance crashes caused by a single too large update.
- Hyperparameter Robust: Convergence can be achieved without a large number of parameter adjustments, suitable for project implementation
- Support continuous/discrete mixed space: Although this project discretizes actions, PPO’s framework naturally supports more complex action space expansion
The objective function of PPO is:
Where
3.2 Network structure
The policy network uses MlpPolicy (multi-layer perceptron):
- Shared Feature Layer: Two 128-unit fully connected layers + ReLU activation
- Policy Header: Outputs the logarithmic probability of a 3-dimensional discrete action
- Value Header: Output state value estimate
Training hyperparameters:| Parameter | Value | |------|-----| | Learning rate | 3e-4 | | GAE λ | 0.95 | | Discount factor γ | 0.99 | | Number of steps per round n_steps | 2048 | | batch size | 64 | | Entropy coefficient ent_coef | 0.01 |
4. Action space and observation space
4.1 Action space (3-dimensional discrete)
| action | value | behavior |
|---|---|---|
| Keep lane | 0 | Drive at a constant speed in the current lane |
| Change lanes to the left | 1 | Initiate a lane change to the left lane |
| Change lanes to the right | 2 | Initiate a lane change to the right lane |
4.2 Observation space (14-dimensional continuous vector)
The observation vector contains three types of information:
Main vehicle status (3D)
- Longitudinal velocity
(normalized) - Lateral velocity
(normalized) - Target cruise speed (normalized, TARGET_SPEED = 50 km/h)
Surrounding vehicle perception (10 dimensions) Using a 5-channel sensor configuration, each channel returns “nearest vehicle distance” + “relative speed”:
[左后] [左前]
↑
[后] ←—— [主车] ——→ [前]
↓
[右后] [右前]Road Information (1D)
can_l: whether the left lane can be changed (Boolean)can_r: whether the right lane can be changed (Boolean)st_code: Lane changing cooling status
5. Reward function design
The reward function is the core driving force of policy learning. This project adopts a mixed design of dense rewards + sparse incentives:
5.1 Rewards for each component
Speed Bonus (r_speed)
When reaching the target speed of 50 km/h, the reward is 1.0; at lower speeds, the reward is smaller.
Traffic jam penalty
This is the core driving force that drives the agent to actively change lanes - points will continue to be deducted if trapped behind a slower vehicle.Reward for successful lane change
A lane change is considered successful if and only if: a lane change is detected within 35 steps after the lane change cooling is completed. High rewards establish a strong association of “change lane → success”.
Safety Penalty
Collisions are high voltage lines and are not acceptable under any circumstances.
5.2 Reward signal analysis
Why is it designed this way?
The traffic jam penalty is set to not too heavy (-0.5) because if it is too heavy, the agent will “would rather crash than change lanes”; and the collision penalty is set to extremely heavy (-50) because safety must override everything else. Through multi-component weighted combination, the strategy finally learns to actively change lanes to avoid congestion under the premise of safety.
6. Training results and analysis
6.1 Training configuration
- Map: CARLA Town06 (urban road, two-way multi-lane)
- Simulation step: 0.1 seconds
- Target number of training steps: 1 million steps (1M steps)
- Device: CPU training (GPU acceleration mainly benefits from the parallelism of physics simulation)
- CHECKPOINT SAVE: Save every 10,000 steps
6.2 Training Curve
After 270,000 steps of training (corresponding to about 7.5 hours), the agent has demonstrated clear lane-changing capabilities:
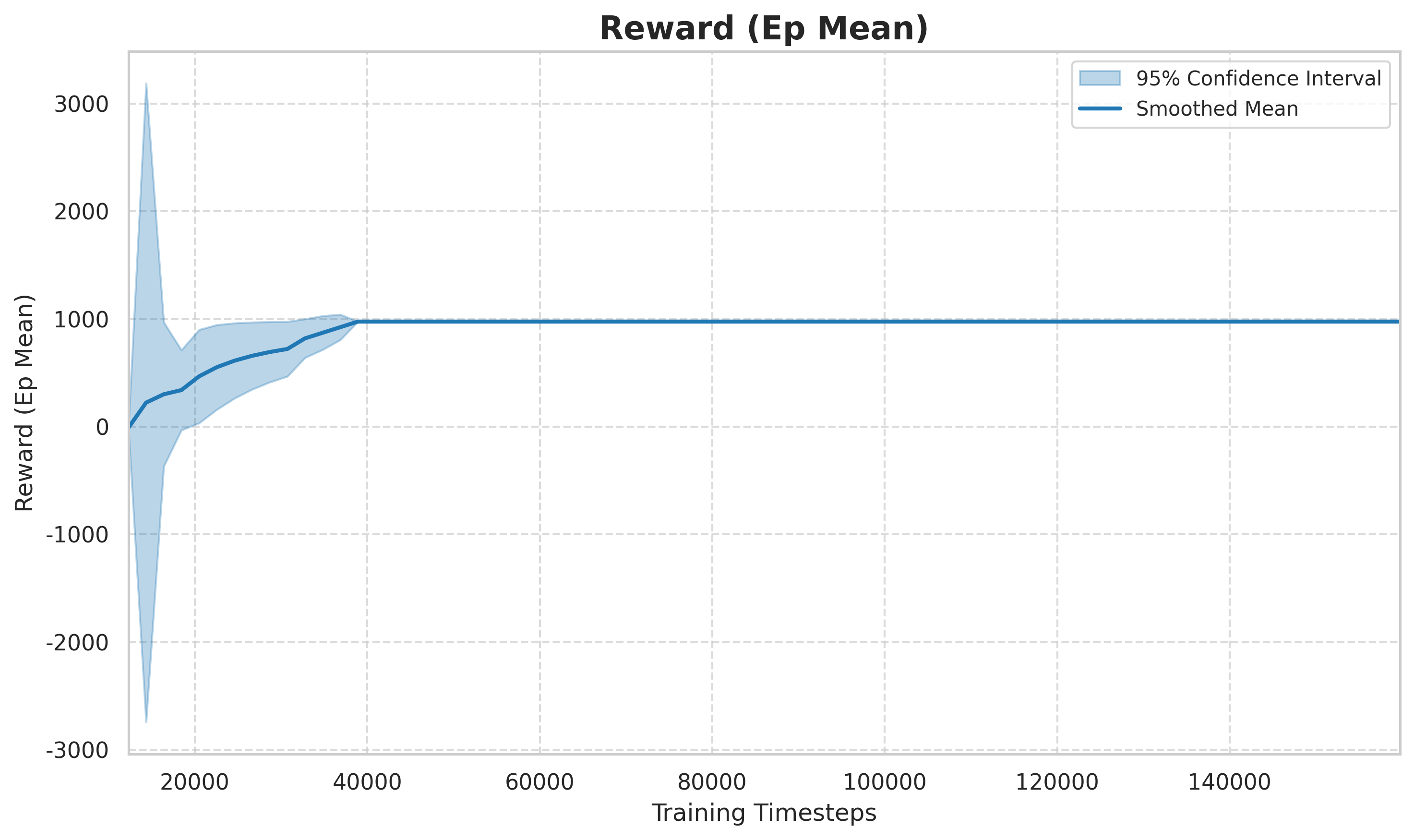
Figure: The average reward per episode (episode reward mean) changes with the number of training steps. In the early stage (0
50k steps), the reward fluctuates violently, and the agent is in the random exploration stage; in the middle stage (50k150k steps), the reward rises rapidly, and the strategy gradually learns to change lanes to obtain higher speed rewards; in the later stage (150k+ steps), it tends to converge, and the strategy is close to the suboptimal solution.
6.3 Value loss and strategy loss
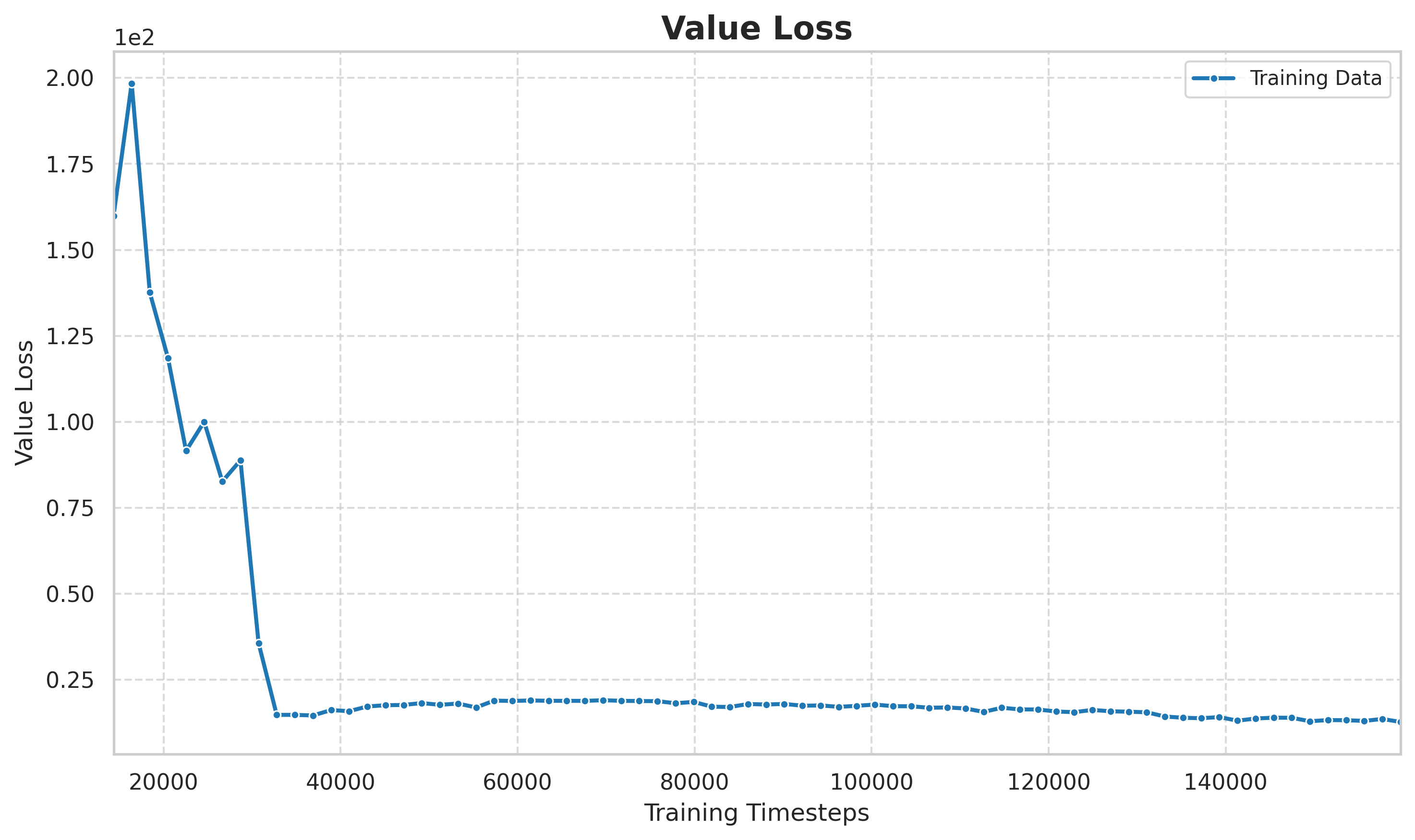 > Figure: Value loss changes with the number of training steps. The initial loss is high, and the value network is still learning to estimate the state value; the loss in the middle and later stages stabilizes at a low level, indicating that the value estimation tends to be accurate, providing a reliable baseline for the advantage function.
> Figure: Value loss changes with the number of training steps. The initial loss is high, and the value network is still learning to estimate the state value; the loss in the middle and later stages stabilizes at a low level, indicating that the value estimation tends to be accurate, providing a reliable baseline for the advantage function.
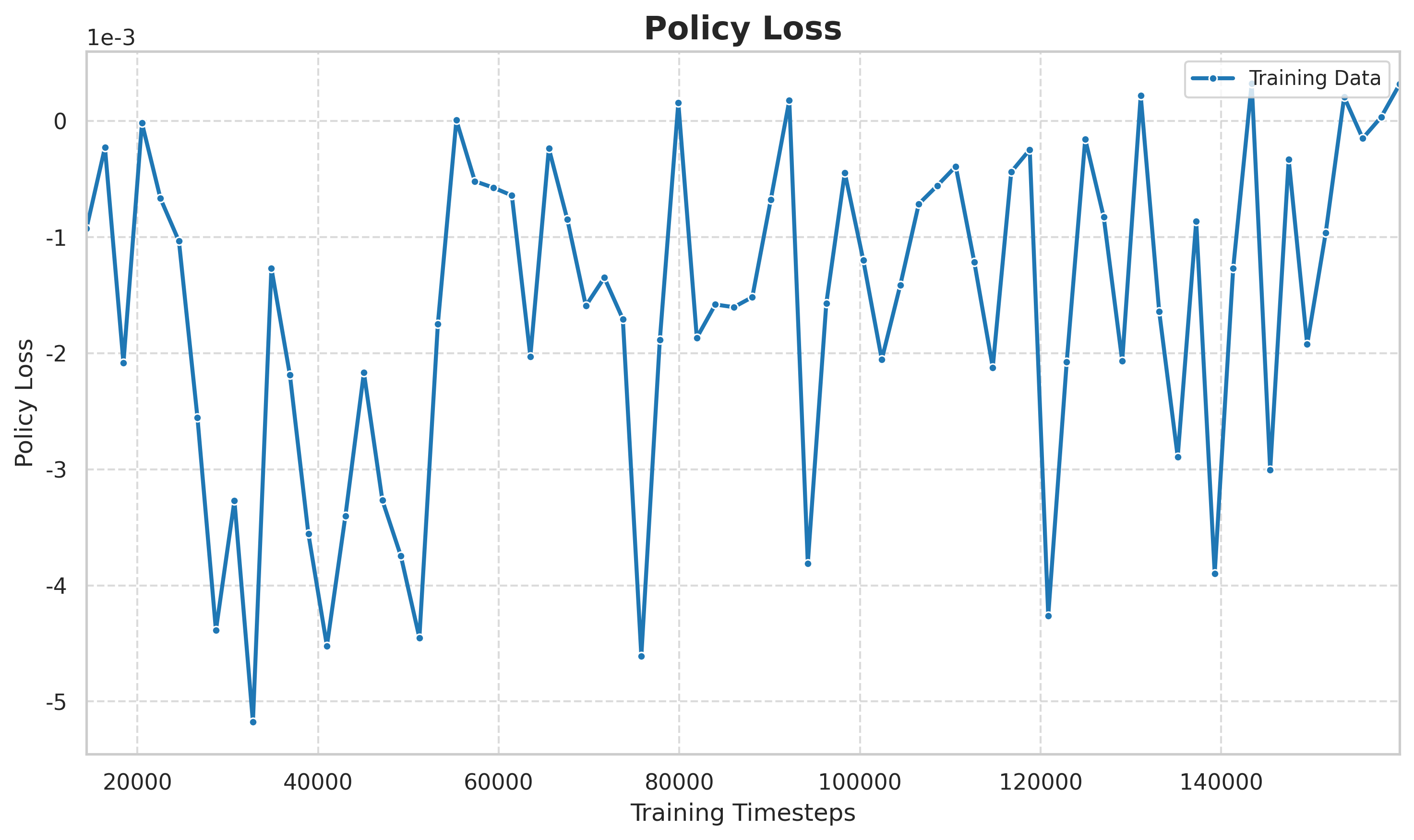
Figure: Policy loss curve. The strategy loss of PPO directly reflects the direction and magnitude of strategy update, and it can be seen that the strategy is dynamically adjusted between exploration and exploitation.
6.4 Speed comparison analysis
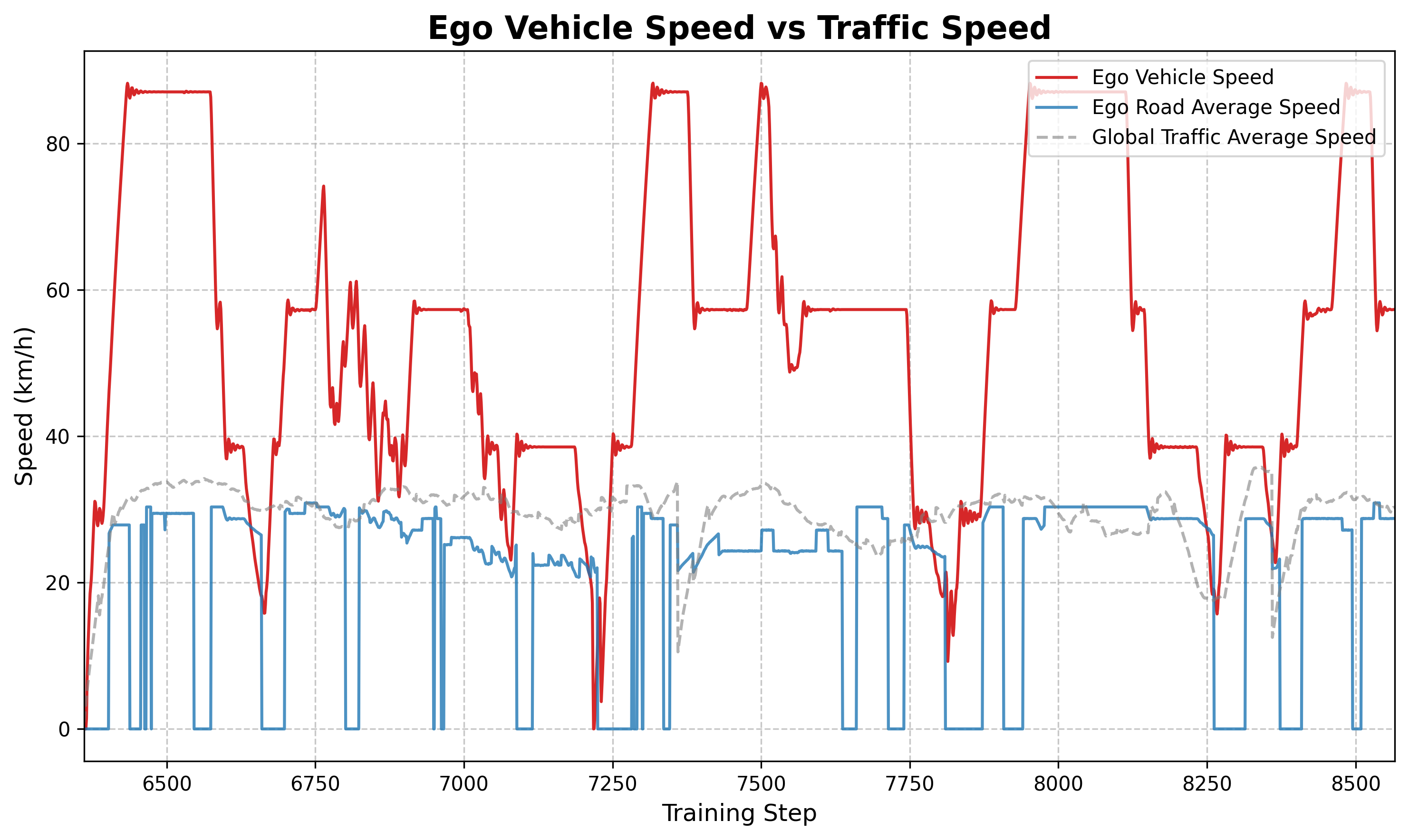
Figure: Comparison of main vehicle speed (orange) vs. average road speed (blue). It can be observed that the overall speed of the main vehicle is higher than the average speed of traffic flow, indicating that the strategy has learned to actively find high-speed lanes or get rid of low-speed congestion.
6.5 Lane changing frequency analysis
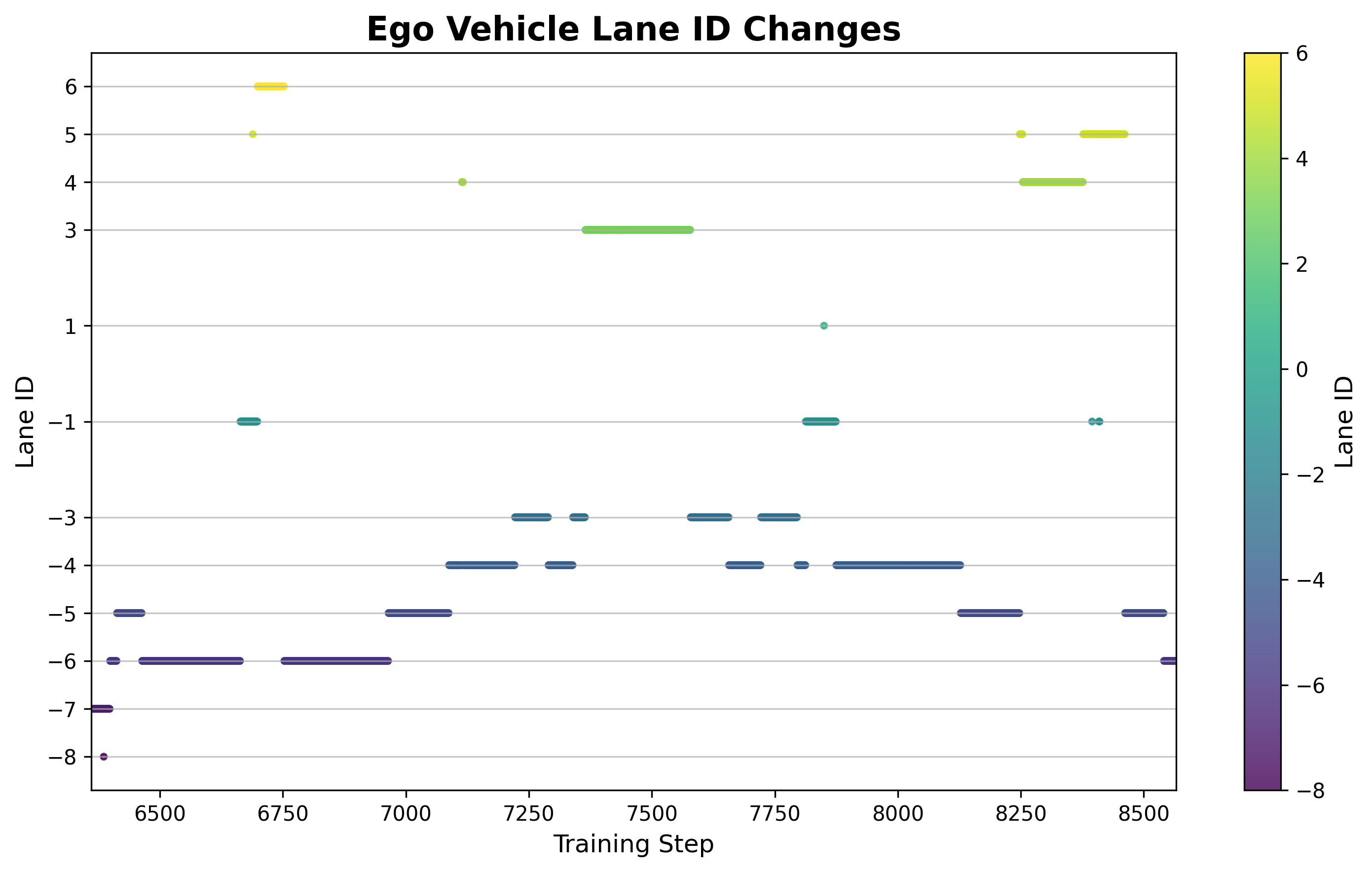
Figure: Changes in the cumulative number of lane changes during training. In the early stage, lane changes were frequent but inefficient (a large number of failed lane changes). In the middle and late stages, lane changes were reduced but the success rate was significantly improved. The strategy learned to change lanes when necessary instead of blindly changing lanes.
6.6 Saved Checkpoints
The project saves 30 checkpoints in the checkpoints/ directory, covering the complete training process from 10,000 steps to 270,000 steps:
ppo_carla_autodrive_10006_steps.zip
ppo_carla_autodrive_20253_steps.zip
ppo_carla_autodrive_30253_steps.zip
...
ppo_carla_autodrive_270489_steps.zipEach checkpoint step can be used for interruption recovery and strategy comparison experiment.
7. Key code implementation details
7.1 BridgeHelper: Coordinate conversion
CARLA uses a left-handed coordinate system (X front, Y right, Z up), SUMO uses a right-handed coordinate system, and the two axes are opposite. BridgeHelper implements this conversion:
# 位置转换:SUMO → CARLA
carla_location = carla.Location(
x=sumo_x,
y=-sumo_y, # Y 轴取反
z=0.5
)
# 朝向角转换
carla_rotation = carla.Rotation(
pitch=0,
yaw=math.degrees(-sumo_angle), # 角度取反
roll=0
)7.2 Deadlock detection and cleaning
Background cars in SUMO may be stuck in a deadlock due to red lights, congestion, etc. This project implements intelligent deadlock detection:
def _check_and_remove_deadlock(self, vehicle_id):
speed = traci.vehicle.getSpeed(vehicle_id)
wait_time = traci.vehicle.getAccumulatedWaitingTime(vehicle_id)
if speed < 0.1:
if self._is_at_red_light(vehicle_id) and wait_time > 120:
traci.vehicle.remove(vehicle_id) # 红灯等待超时,移除
elif wait_time > 10:
traci.vehicle.remove(vehicle_id) # 非红灯死锁,快速清理7.3 Custom callback: TrafficLoggerCallbackDuring the training process, traffic data is automatically recorded to CSV for subsequent analysis:
class TrafficLoggerCallback(BaseCallback):
def _on_step(self) -> bool:
infos = self.locals["infos"][0]
self.writer.writerow([
self.num_timesteps,
infos.get('ego_speed_kmh', 0.0),
infos.get('average_speed', 0.0),
infos.get('ego_road_avg_speed', 0.0),
infos.get('current_lane_id', -1)
])
return True8. Project structure overview
carlaSumoRL/
├── assets/ # SUMO 地图配置、Town06 路网
│ ├── Town06.rou.xml # 交通流生成配置
│ ├── Town06.net.xml # SUMO 路网定义
│ ├── town06.sumocfg # SUMO 仿真配置文件
│ └── *.png # 可视化结果图
├── core/ # 核心仿真逻辑
│ ├── bridge_helper.py # 坐标系转换(368行)
│ ├── carla_simulation.py # CARLA 仿真控制(186行)
│ ├── sumo_simulation.py # SUMO 仿真控制(517行)
│ └── constants.py # 常量定义
├── envs/
│ └── carla_sumo_env.py # Gym 环境定义(469行)
├── checkpoints/ # 30个训练检查点
├── ppo_carla_tensorboard/ # TensorBoard 日志
├── train_ppo.py # 训练入口
├── test_ppo.py # 测试入口
├── plot_training_curve.py # 训练曲线可视化
├── plot_metrics.py # 交通数据分析
└── traffic_log.csv # 实时交通数据日志9. Limitations and future work
Current limitations
- Limited observation space: Only 5-channel ray sensor is used, visual input is not used, and the sensory information is insufficient in high-speed scenes.
- Single-Master Vehicle Scenario: Multi-agent collaboration is not yet supported, and the interactive game of multiple vehicles changing lanes at the same time has not been modeled.
- SUMO vehicle behavior is simple: The background car uses the default IDM car-following model and lacks the differentiation of aggressive/conservative driving styles.
- Lane changing decision depends on cooling time: Lane changing in real driving requires multi-stage coordination of perception-decision-execution, and the current model has been greatly simplified.
Future Directions
- Introducing image input: Use CNN or Vision Transformer to process vehicle camera data to implement an end-to-end vision strategy
- Multi-agent expansion: Introduce multiple self-driving main vehicles to study interactive games and confrontation scenarios
- Course Learning: Gradually transition from simple scenarios (empty roads) to complex scenarios (high-density traffic, ramp merging)
- Real Road Verification: Migrate the trained strategy to the Carla_ROS framework and verify it on a real vehicle or hardware-in-the-loop platform
10. Summary
This project completely implements a CARLA-SUMO collaborative simulation + PPO reinforcement learning autonomous driving lane-changing training framework. Through the collaboration of dual simulators, it not only ensures the authenticity of the main vehicle dynamics, but also ensures the diversity and challenge of the background traffic flow.
The project code size is about 1540 lines, with a clear structure, covering the entire training-testing-visualization process, and 30 checkpoints have been saved for reproduction and secondary development. If you are interested in autonomous driving decision planning and the application of reinforcement learning in traffic scenarios, this framework is a good starting point.
Project address: /home/tartlab/project/outwork/carlaSumoRL/
Author: Kagura Tart | 2026-04-15