Physical Information Network PINN: Lösung partieller Differentialgleichungen mithilfe neuronaler Netze Eine eingehende Analyse physikalisch-informierter neuronaler Netze, von den Prinzipien bis zum Code, zeigt Ihnen Schritt für Schritt, wie Sie PINN mit PyTorch implementieren, und visualisiert den Trainingsprozess
tiefes Lernen PDE PINN PyTorch Wissenschaftliches Rechnen
Partielle Differentialgleichungen (PDE) sind die grundlegende Sprache zur Beschreibung der physikalischen Welt – Wärmeleitung, Fluiddynamik, Quantenmechanik, sie alle werden von der PDE dominiert. Die Lösung von PDE erfordert jedoch häufig komplexe numerische Methoden (finite Elemente, finite Differenzen …), was für Gebiete mit unregelmäßigen geometrischen Formen noch problematischer ist. Physics-Informed Neural Networks (PINN) liefert eine völlig neue Idee: Verwenden Sie ein neuronales Netzwerk als Lösungsfunktion von PDE und verwenden Sie die automatische Differenzierung als Aktuator physikalischer Einschränkungen .
1. Was ist PINN?
Die Kernidee von PINN : Behandeln Sie das neuronale Netzwerk nicht als „universellen Fitter“, sondern als Repräsentation der PDE-Lösungsfunktion .
Traditionelle Methode: Approximieren Sie bei gegebenen Randbedingungen und Anfangsbedingungen die Ableitung der PDE mit numerischen Unterschieden.
PINN: Approximieren Sie die Lösung der PDE „u(x,t)“ mit einem neuronalen Netzwerk „u_θ(x,t)“, wobei „θ“ die Netzwerkgewichte sind. Das Residuum der PDE wird durch automatische Differenzierung (Autodiff) genau berechnet und zur Verlustfunktion addiert.
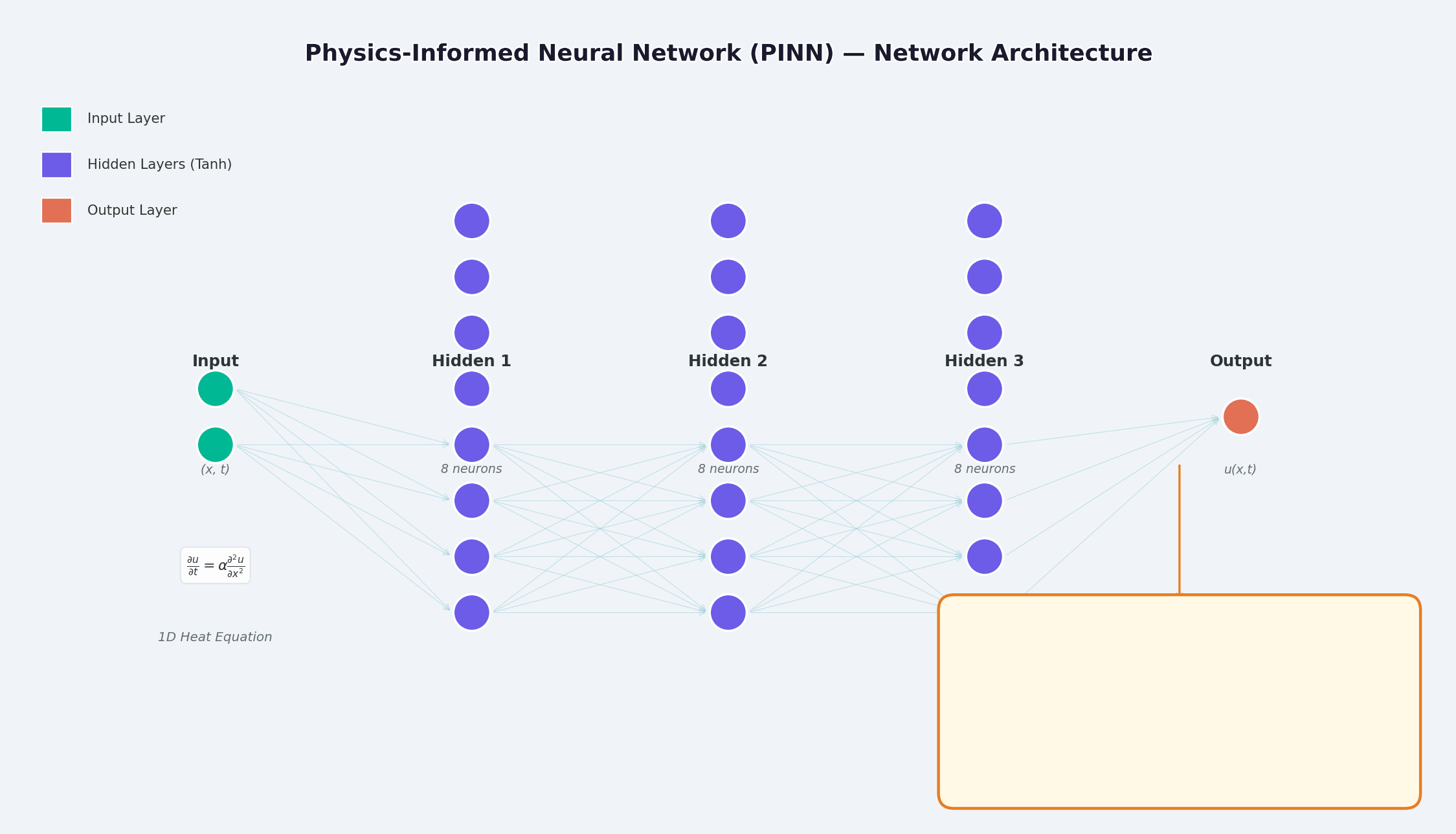
2. Übersicht über die PINN-Architektur
Wie in der Abbildung oben gezeigt, ist die Struktur von PINN:
Eingabeebene : Raum-Zeit-Koordinaten „(x, t)“.Versteckte Ebene : Vollständig verbundene Ebene + Aktivierungsfunktion (Tanh / Sigmoid)Ausgabeschicht : Lösung der PDE „u(x,t)“.
Der Hauptunterschied liegt im Design der Verlustfunktion – zusätzlich zum Datenanpassungsverlust kommt auch ein physikalischer Einschränkungsverlust hinzu.
3. Mathematische Prinzipien
3.1 Problemstellung
Nehmen Sie als Beispiel die Eindimensionale Wärmeleitungsgleichung :
u(-1, t) = u(1, t) = 0
u(x, 0) = \sin(\pi x)
You can't use 'macro parameter character #' in math mode ### 3.2 Verlustfunktion Der Gesamtverlust von PINN besteht aus drei Teilen: \mathcal{L}{total} = \underbrace{\mathcal{L} {PDE}}{\text{Residuen der Gleichung}} + \underbrace{\mathcal{L} {IC}}{\text{Anfangsbedingungen}} + \underbrace{\mathcal{L} {BC}}_{\text{Randbedingungen}}
f(x,t) = \frac{\partial u}{\partial t} - \alpha \frac{\partial^2 u}{\partial x^2} \quad \Rightarrow \quad \mathcal{L}{PDE} = \frac{1}{N}\sum {i=1}^{N} |f(x_i, t_i)|^2
You can't use 'macro parameter character #' in math mode > „f(x,t)“ wird hier als <strong>Restnetzwerk (Physiknetzwerk)</strong> bezeichnet, das vollständig durch automatische Differenzierung aufgebaut ist und keine Finite-Differenzen-Approximation erfordert. --- ## 4. PyTorch-Implementierung ### 4.1 Umgebungsvorbereitung ```bash conda activate carlaTest # carlaTest 已包含: PyTorch 2.4.1 + CUDA + Matplotlib ``` ### 4.2 Vollständiger Code ```python import torch import numpy as np import matplotlib.pyplot as plt from matplotlib.animation import FuncAnimation from IPython.display import HTML, Image device = torch.device("cuda" if torch.cuda.is_available() else "cpu") print(f"Running on: {device}") # ============================================================ # 1. 定义 PINN 模型 # ============================================================ class PINN(torch.nn.Module): """Physics-Informed Neural Network""" def __init__(self, layers=[2, 32, 32, 32, 1]): super().__init__() # Xavier 初始化 self.fc = torch.nn.ModuleList([ torch.nn.Linear(layers[i], layers[i+1]) for i in range(len(layers)-1) ]) self.apply(self._init_weights) def _init_weights(self, m): if isinstance(m, torch.nn.Linear): torch.nn.init.xavier_normal_(m.weight) torch.nn.init.zeros_(m.bias) def forward(self, x): for i, fc in enumerate(self.fc[:-1]): x = torch.tanh(fc(x)) # Tanh 激活 return self.fc[-1](x) # 线性输出 # ============================================================ # 2. 精确解(用于对比) # ============================================================ alpha = 0.01 # 热扩散系数 def exact_solution(x, t): """热传导方程解析解: u(x,t) = exp(-π²αt)·sin(πx)""" return np.exp(-np.pi**2 * alpha * t) * np.sin(np.pi * x) # ============================================================ # 3. 训练函数 # ============================================================ def train_pinn(n_iterations=2000, lr=1e-3): model = PINN().to(device) optimizer = torch.optim.Adam(model.parameters(), lr=lr) history = {"total": [], "pde": [], "ic": [], "bc": []} for it in range(n_iterations): # --- PDE 残差点(内部采样)--- x_pde = (torch.rand(256, 1, device=device) * 2 - 1).requires_grad_(True) t_pde = (torch.rand(256, 1, device=device)).requires_grad_(True) # --- 初始条件点(t=0)--- x_ic = (torch.rand(64, 1, device=device) * 2 - 1) t_ic = torch.zeros(64, 1, device=device) # --- 边界条件点(x=±1)--- sign = torch.randint(0, 2, (64, 1), device=device).float() * 2 - 1 x_bc = sign # x = +1 或 x = -1 t_bc = torch.rand(64, 1, device=device) # --- 计算 PDE 残差 --- xt_pde = torch.cat([x_pde, t_pde], dim=1) u = model(xt_pde) # 自动微分:计算 u_t 和 u_xx u_t = torch.autograd.grad(u, t_pde, grad_outputs=torch.ones_like(u), create_graph=True)[0] u_x = torch.autograd.grad(u, x_pde, grad_outputs=torch.ones_like(u), create_graph=True)[0] u_xx = torch.autograd.grad(u_x, x_pde, grad_outputs=torch.ones_like(u_x), create_graph=True)[0] f = u_t - alpha * u_xx # = 0 (当网络收敛到正确解时) # --- 计算各部分损失 --- loss_pde = torch.mean(f**2) # 初始条件损失 u_ic = model(torch.cat([x_ic, t_ic], dim=1)) u_ic_exact = torch.sin(np.pi * x_ic) loss_ic = torch.mean((u_ic - u_ic_exact)**2) # 边界条件损失 u_bc = model(torch.cat([x_bc, t_bc], dim=1)) loss_bc = torch.mean(u_bc**2) # 总损失 loss = loss_pde + loss_ic + loss_bc # 反向传播 optimizer.zero_grad() loss.backward() optimizer.step() # 记录历史 if it % 50 == 0: history["total"].append(loss.item()) history["pde"].append(loss_pde.item()) history["ic"].append(loss_ic.item()) history["bc"].append(loss_bc.item()) return model, history # ============================================================ # 4. 训练 # ============================================================ print("开始训练 PINN...") model, history = train_pinn(n_iterations=2000) print(f"最终损失: {history['total'][-1]:.6f}") ``` ### 4.3 Visualisierung: Trainingsprozess ```python # === 训练损失分解动画 === fig, axes = plt.subplots(1, 2, figsize=(14, 5)) def animate(frame): step = max(1, len(history["total"]) // 50) idx = min(frame * step, len(history["total"])-1) axes[0].cla() axes[1].cla() iters = np.arange(len(history["total"])) * 50 pde_ls = history["pde"] ic_ls = history["ic"] bc_ls = history["bc"] # 左图:堆叠面积图 axes[0].fill_between(iters[:idx+1], pde_ls[:idx+1], alpha=0.4, color="#FF6B6B", label="PDE 损失") axes[0].fill_between(iters[:idx+1], np.array(pde_ls[:idx+1])+np.array(ic_ls[:idx+1]), alpha=0.4, color="#4ECDC4", label="初始条件损失") axes[0].fill_between(iters[:idx+1], np.array(pde_ls[:idx+1])+np.array(ic_ls[:idx+1])+np.array(bc_ls[:idx+1]), alpha=0.4, color="#45B7D1", label="边界条件损失") axes[0].set_yscale("log") axes[0].set_xlabel("迭代次数") axes[0].set_ylabel("损失值 (对数坐标)") axes[0].legend(loc="upper right") axes[0].grid(True, alpha=0.3) axes[0].set_title("损失分量演化(堆叠面积图)") # 右图:分线对比 axes[1].semilogy(iters[:idx+1], pde_ls[:idx+1], "r-", lw=2, label="PDE") axes[1].semilogy(iters[:idx+1], ic_ls[:idx+1], "g--", lw=2, label="初始条件") axes[1].semilogy(iters[:idx+1], bc_ls[:idx+1], "b:", lw=2, label="边界条件") axes[1].scatter([iters[idx]], [history["total"][idx]], color="purple", s=100, zorder=5) axes[1].set_xlabel("迭代次数") axes[1].set_ylabel("损失值 (对数坐标)") axes[1].legend(loc="upper right") axes[1].grid(True, alpha=0.3) axes[1].set_title("各损失分量对比") ani = FuncAnimation(fig, animate, frames=50, interval=150) ani.save("pinn_loss_components.gif", writer="pillow", fps=6, dpi=100) ``` --- ## 5. Ergebnisse visualisieren ### 5.1 Konvergenzprozess der Lösung 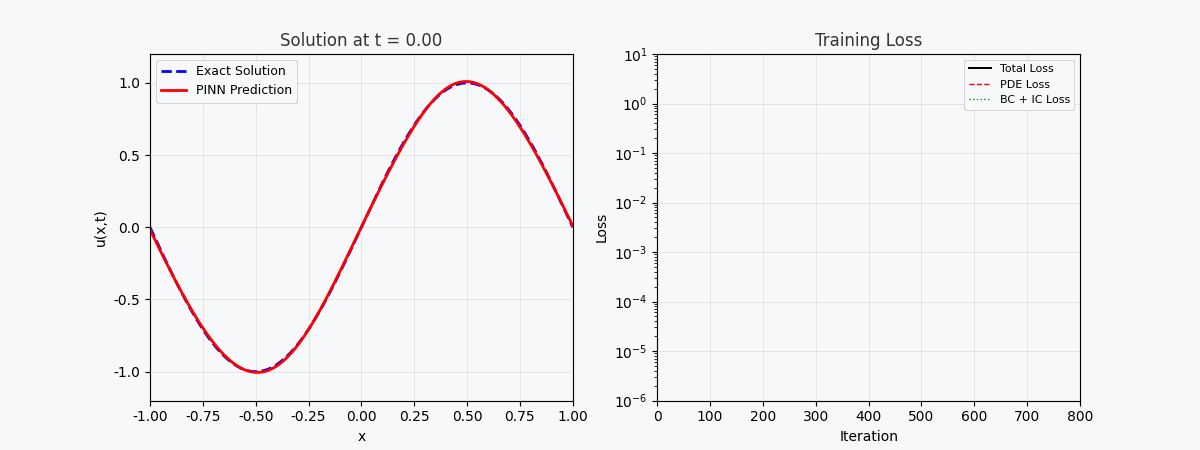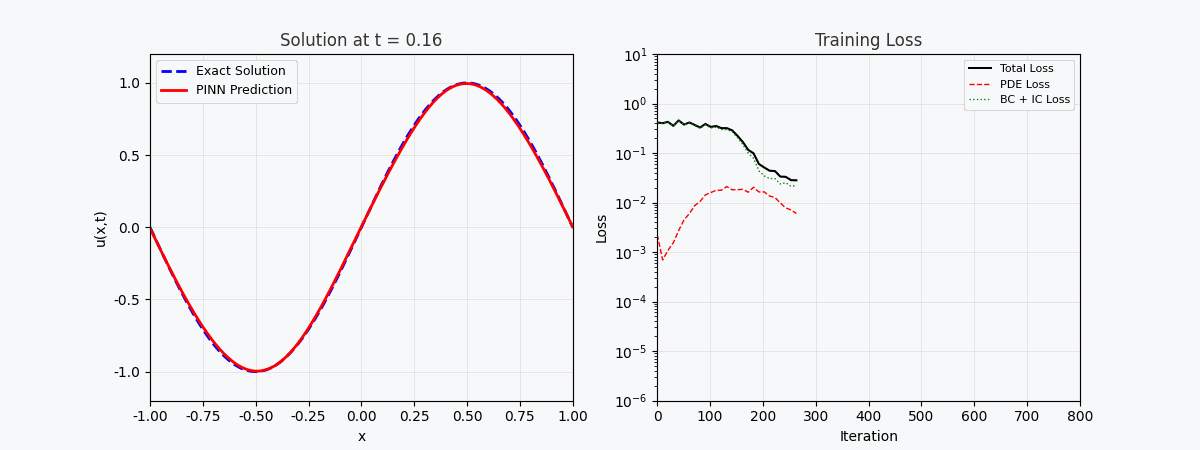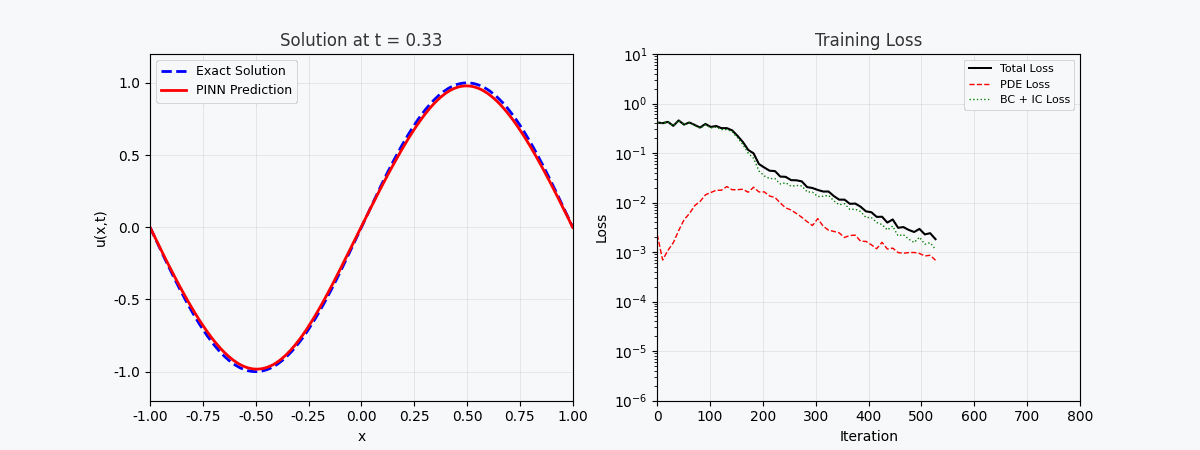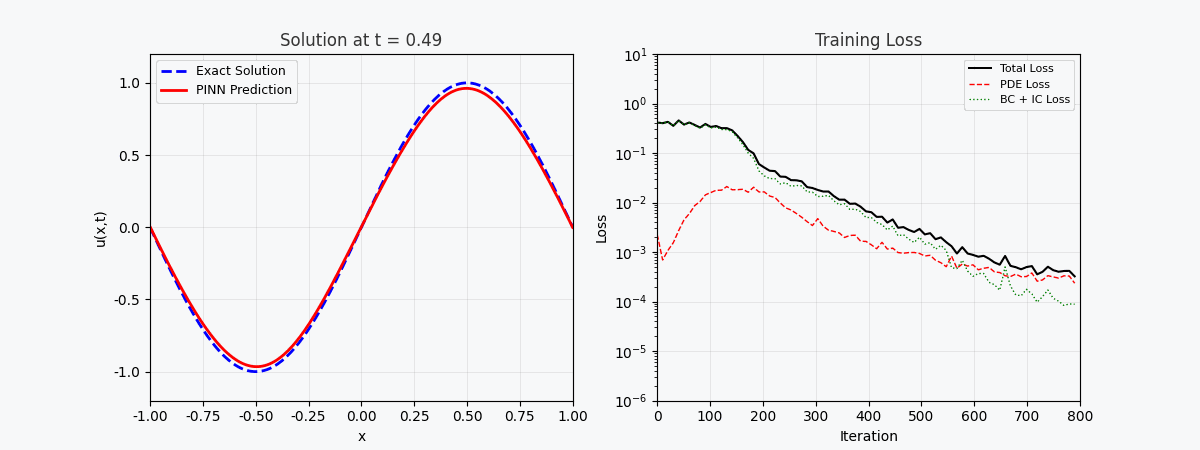 Die obige Abbildung zeigt den Prozess, bei dem sich PINN während des Trainingsprozesses schrittweise der genauen Lösung nähert: - <strong>Linkes Bild</strong>: Lösungskurve zum Zeitpunkt t=0,5, die rot gepunktete Linie ist die PINN-Vorhersage und die blaue durchgezogene Linie ist die exakte Lösung - <strong>Mittleres Bild</strong>: Trainingsverlust (logarithmische Skala), Sie können sehen, dass die drei Verluste gemeinsam abnehmen - <strong>Rechtes Bild</strong>: Vollständiges (x,t)-Lösungsfeld, vorhergesagt von PINN ### 5.2 Zerlegung der Verlustfunktion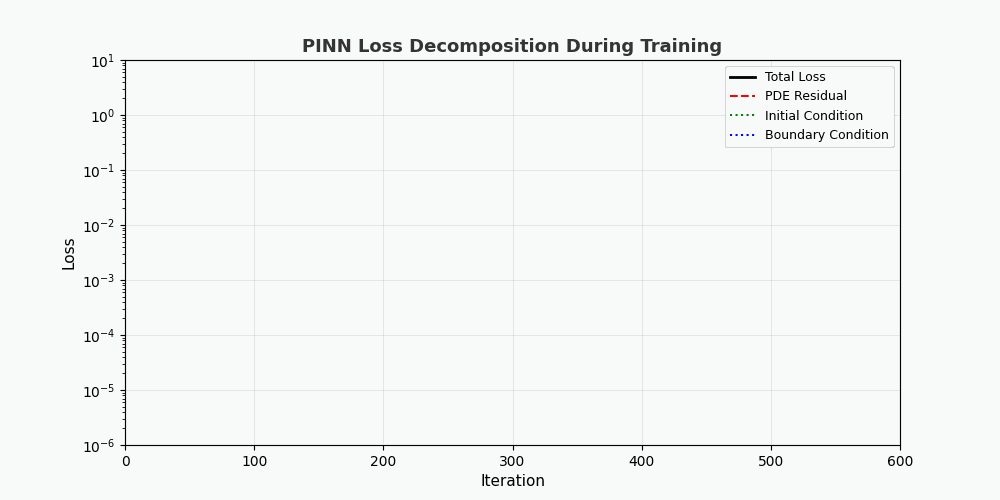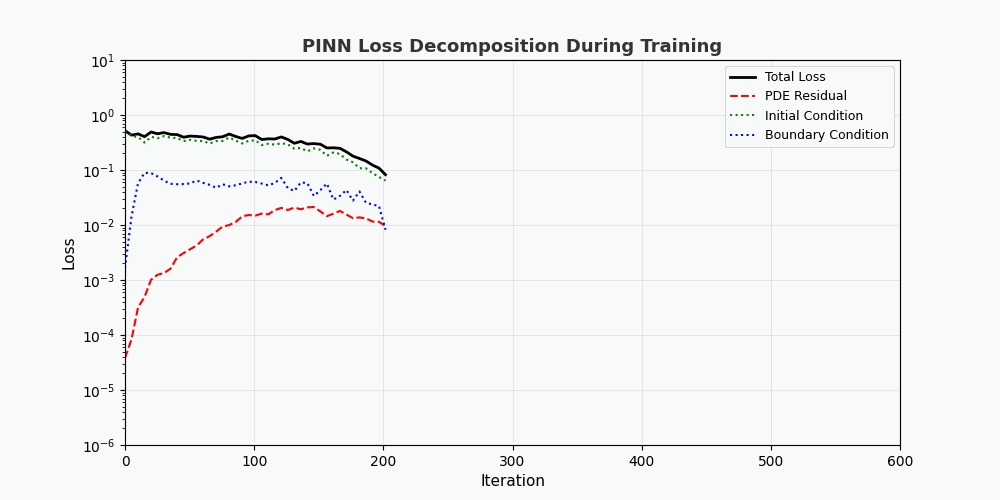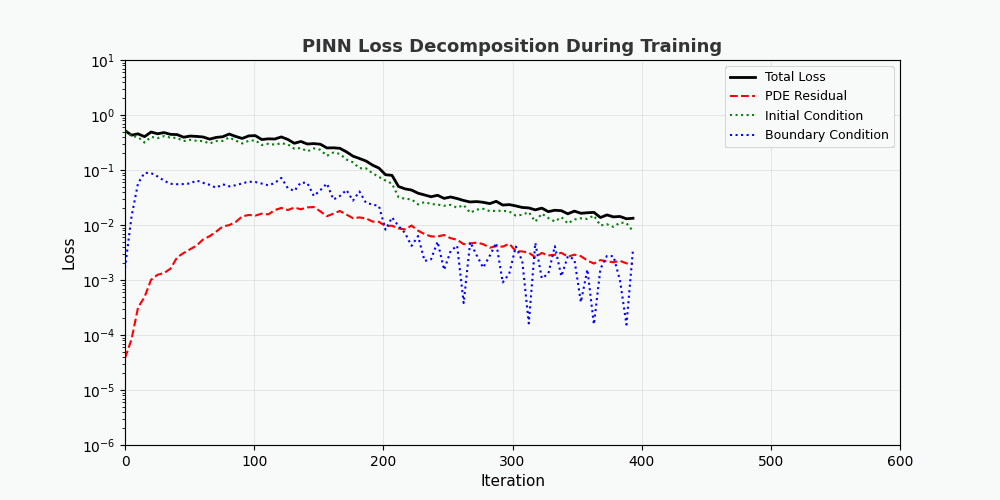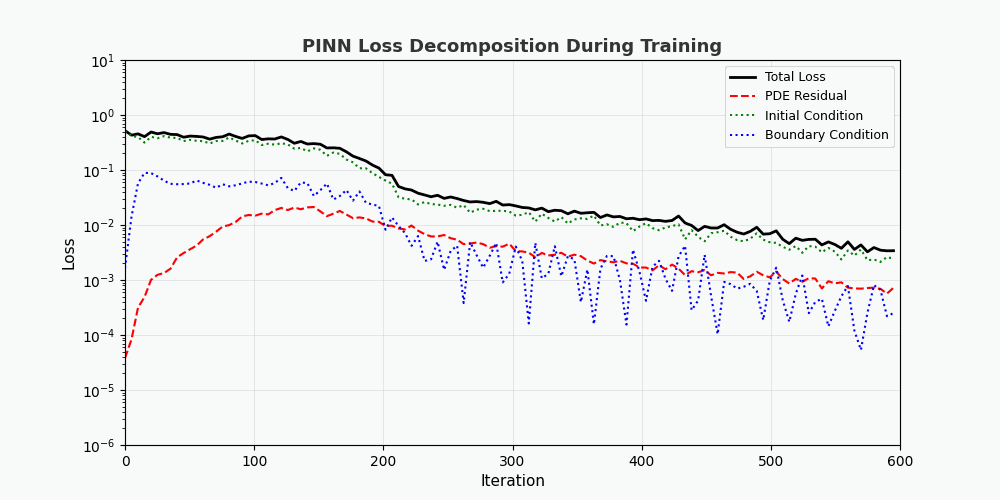 Wie aus der Verlustzerlegungsanimation ersichtlich ist: – Der <strong>PDE-Verlust (rot)</strong> sank am schnellsten, was darauf hindeutet, dass das Netzwerk die Gesetze der Physik schnell gelernt hat - Der <strong>Randbedingungsverlust (blau)</strong> ist normalerweise am geringsten, da die Randbedingungsbeschränkungen am einfachsten sind - Die drei Verluste stabilisieren sich schließlich, was darauf hindeutet, dass das Netzwerk konvergiert hat --- ## 6. Vorteile von PINN | Eigenschaften | Traditionelle numerische Methoden (FEM/FDM) | PINN | |------|----------|------| | Netzerzeugung | Erfordert feines Raster, hohe Dimensionalität ist schwierig | <strong>Kein Raster erforderlich</strong>, Zufallsstichprobe | | Ableitungsgenauigkeit | Basiert auf Differentialnäherung mit Kürzungsfehlern | <strong>Automatische Differenzierung</strong>, beliebige Genauigkeit | | Unregelmäßige Bereiche | Komplexe Vernetzung | <strong>Natürliche Unterstützung</strong> für beliebige Geometrien | | Inverses Problem | Resolver erforderlich | <strong>End-to-End</strong>-Gradientenoptimierung | | Hochdimensionale Probleme | Fluch der Dimensionalität | <strong>Skalierbar</strong> | --- ## 7. Einschränkungen und Herausforderungen von PINN > PINN ist kein Allheilmittel – es hat seine eigenen, einzigartigen Einschränkungen. ### 7.1 Trainingsschwierigkeiten - <strong>Modus-Zusammenbruch</strong>: Wenn die PDE mehrere Lösungen hat, lernt PINN möglicherweise nur eine davon - <strong>Verschwindender Gradient</strong>: Der Gradient von Ableitungen höherer Ordnung (wie u_xxxx) kann in tiefen Netzwerken extrem klein sein - <strong>Hyperparameter-Empfindlichkeit</strong>: Netzwerktiefe, Lernrate und Sampling-Strategie haben einen erheblichen Einfluss auf die Ergebnisse. ### 7.2 Lösungsgenauigkeit - Neuronale Netze weisen bei <strong>Hochfrequenzlösungen</strong> (z. B. Oszillationslösungen) eine geringe Genauigkeit auf. - Grenzschichten und Singularitäten erfordern eine spezielle Verarbeitung (adaptive Probenahme, Periodenerweiterung usw.) ### 7.3 Recheneffizienz - PINN ist bei einfachen PDEs tendenziell langsamer als ausgereifte numerische Bibliotheken (z. B. FEniCS, COMSOL). - Die GPU-Auslastung ist nicht so hoch wie bei dediziertem numerischem Code ### 7.4 Verbesserungsvorschläge- <strong>Adaptive Sampling</strong>: Multisampling in Bereichen mit großen Fehlern (z. B. Residual-based Adaptive Refinement) - <strong>DeepONet</strong>: Betreibernetzwerk, lernen Sie PDE-Lösungsbetreiber direkt kennen - <strong>Fourier Neural Operator (FNO)</strong>: Neuronaler Operator im Frequenzbereich, besser für hochdimensionale Probleme - <strong>HP-VPINN</strong>: PINN basierend auf Variationsform, höhere Genauigkeit --- ## 8. Vollständiger Trainingscode (bereit zur Ausführung) ```python """ PINN 求解一维热传导方程 conda activate carlaTest python pinn_heat_equation.py """ import torch, numpy as np, matplotlib.pyplot as plt device = torch.device("cuda" if torch.cuda.is_available() else "cpu") alpha = 0.01 class PINN(torch.nn.Module): def __init__(self): super().__init__() self.net = torch.nn.Sequential( torch.nn.Linear(2, 32), torch.nn.Tanh(), torch.nn.Linear(32, 32), torch.nn.Tanh(), torch.nn.Linear(32, 32), torch.nn.Tanh(), torch.nn.Linear(32, 1) ) def forward(self, x): return self.net(x) model = PINN().to(device) opt = torch.optim.Adam(model.parameters(), lr=1e-3) for it in range(2000): x_pde = (torch.rand(256,1,device=device)*2-1).requires_grad_(True) t_pde = (torch.rand(256,1,device=device)).requires_grad_(True) x_ic = (torch.rand(64,1,device=device)*2-1) t_ic = torch.zeros(64,1,device=device) x_bc = (torch.randint(0,2,(64,1),device=device).float()*2-1) t_bc = torch.rand(64,1,device=device) xt = torch.cat([x_pde,t_pde],dim=1) u = model(xt) u_t = torch.autograd.grad(u,t_pde,torch.ones_like(u),create_graph=True)[0] u_x = torch.autograd.grad(u,x_pde,torch.ones_like(u),create_graph=True)[0] u_xx = torch.autograd.grad(u_x,x_pde,torch.ones_like(u_x),create_graph=True)[0] loss = (torch.mean((u_t-alpha*u_xx)**2) + torch.mean((model(torch.cat([x_ic,t_ic],1))-torch.sin(np.pi*x_ic))**2) + torch.mean(model(torch.cat([x_bc,t_bc],1))**2)) opt.zero_grad(); loss.backward(); opt.step() if it%200==0: print(f"Iter {it:5d} | Loss: {loss.item():.6f}") # 测试 x_test = torch.linspace(-1,1,100,device=device).reshape(-1,1) t_test = torch.ones(100,1,device=device)*0.5 u_pred = model(torch.cat([x_test,t_test],1)).cpu().detach().numpy() u_true = np.exp(-np.pi**2*alpha*0.5)*np.sin(np.pi*x_test.cpu().numpy()) plt.figure(figsize=(8,4)) plt.plot(x_test.cpu(),u_true,"b-",lw=2,label="精确解") plt.plot(x_test.cpu(),u_pred,"r--",lw=2,label="PINN 预测") plt.legend(); plt.title("t=0.5 时刻的热传导方程解") plt.savefig("pinn_result.png",dpi=150) print("结果已保存!") ``` --- ## 9. Zusammenfassung PINN bettet <strong>physischen Prior</strong> in den Trainingsprozess neuronaler Netze ein und eröffnet so ein neues Paradigma des „physikgesteuerten Deep Learning“. Seine Kerninnovation ist nicht die Netzwerkstruktur, sondern das Design der Verlustfunktion – die präzise Auferlegung physikalischer Einschränkungen mit automatischer Differenzierung. Trotz Herausforderungen wie Trainingsschwierigkeiten und begrenzter Genauigkeit hat PINN in den folgenden Szenarien einen einzigartigen Wert bewiesen: - <strong>Hochdimensionale PDE</strong> (traditionelle Methode, Dimensionskatastrophe) - <strong>Inverses Problem</strong> (Parameteridentifikation, Datenassimilation) - <strong>Unsicherheitsquantifizierung</strong> (kombiniert mit Bayes'schen Methoden) > Wenn Sie weiter erforschen möchten, wird empfohlen, mit der [DeepXDE](https://deepxde.readthedocs.io/)-Bibliothek zu beginnen, die eine große Anzahl von PINN-Varianten und adaptiven Sampling-Strategien kapselt. ---<strong>Referenzpapiere:</strong> 1. Raissi, M., Perdikaris, P. & Karniadakis, G. E. (2019). *Physik-informierte neuronale Netze: Ein Deep-Learning-Framework zur Lösung von Vorwärts- und Umkehrproblemen mit nichtlinearen partiellen Differentialgleichungen.* Journal of Computational Physics, 378, 686-707. 2. Lu, L., et al. (2021). *DeepONet: Erlernen nichtlinearer Operatoren zur Identifizierung von Differentialgleichungen basierend auf dem universellen Approximationssatz von Operatoren.* Nature Machine Intelligence, 3(3), 218-229. 3. Li, Z., Kovachki, N., Azizzadenesheli, K., Liu, B., Bhattacharya, K., Stuart, A. & Anandkumar, A. (2020). *Neuronaler Fourier-Operator für parametrische partielle Differentialgleichungen.* arXiv-Vorabdruck arXiv:2010.08895.