物理情報ネットワーク PINN: ニューラル ネットワークを使用して偏微分方程式を解く
原理からコードに至るまでの物理情報に基づいたニューラル ネットワークの詳細な分析により、PyTorch を使用して PINN を実装する方法を段階的に説明し、トレーニング プロセスを視覚化します。
ディープラーニング偏微分方程式ピンパイトーチ科学計算
偏微分方程式 (PDE) は、熱伝導、流体力学、量子力学などの物理世界を記述するための基本言語であり、それらはすべて PDE によって支配されます。ただし、偏微分方程式を解くには複雑な数値手法 (有限要素、有限差分など) が必要になることが多く、不規則な幾何学的形状を持つ領域ではさらに困難になります。 物理情報に基づいたニューラル ネットワーク (PINN) は、ニューラル ネットワークを PDE の解関数として使用し、 自動微分を物理的制約のアクチュエーターとして使用するというまったく新しいアイデアを提供します。
##1.PINNとは何ですか?
PINN の中心的な考え方: ニューラル ネットワークを「ユニバーサル フィッター」としてではなく、 PDE 解関数の表現 として扱います。
従来の方法: 与えられた境界条件と初期条件を使用して、数値の差を使用して偏微分方程式の導関数を近似します。
PINN: ニューラル ネットワーク u_θ(x,t) を使用して偏微分方程式 u(x,t) の解を近似します。ここで、θ はネットワークの重みです。 PDE の残差は自動微分 (Autodiff) によって正確に計算され、損失関数に追加されます。
2. PINN アーキテクチャの概要
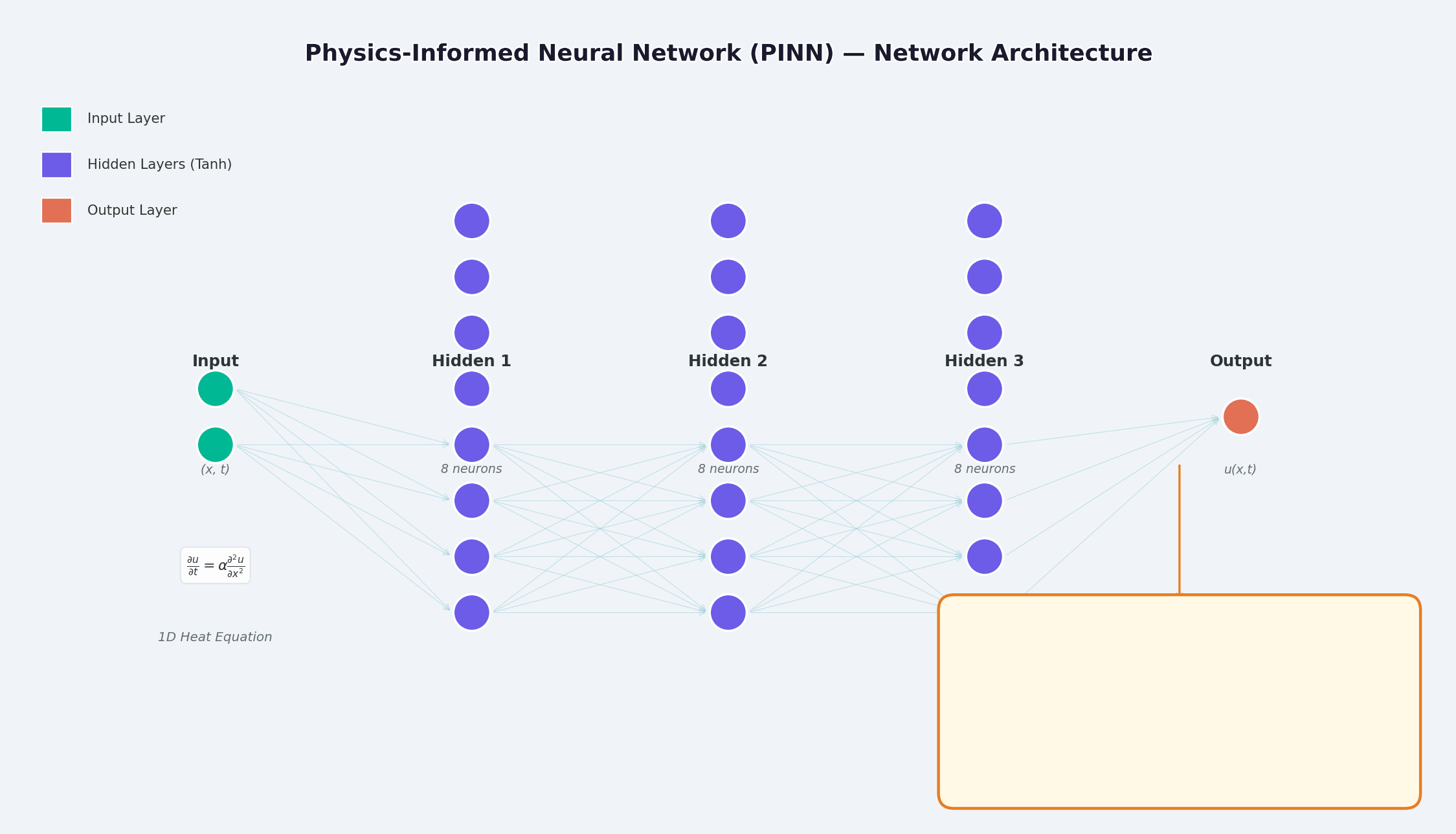
上の図に示すように、PINN の構造は次のとおりです。
- 入力レイヤー: 時空座標
(x, t)
- 隠れ層: 全結合層 + 活性化関数 (Tanh / Sigmoid)
- 出力層: PDE
u(x,t) の解
主な違いは損失関数の設計にあります。データ フィッティング損失に加えて、物理的制約損失も追加されます。
3. 数学的原理
3.1 問題設定
例として一次元の熱伝導方程式を考えてみましょう。
u(-1, t) = u(1, t) = 0
u(x, 0) = \sin(\pi x)
\mathcal{L}{合計} = \underbrace{\mathcal{L}{PDE}}{\text{方程式残差}} + \underbrace{\mathcal{L}{IC}}{\text{初期条件}} + \underbrace{\mathcal{L}{BC}}_{\text{境界条件}}
f(x,t) = \frac{\partial u}{\partial t} - \alpha \frac{\partial^2 u}{\partial x^2} \quad \Rightarrow \quad \mathcal{L}{PDE} = \frac{1}{N}\sum{i=1}^{N} |f(x_i, t_i)|^2