Réseau d'information physique PINN : résolution d'équations aux dérivées partielles à l'aide de réseaux de neurones Une analyse approfondie des réseaux de neurones fondés sur la physique, des principes au code, vous apprend étape par étape comment implémenter PINN à l'aide de PyTorch et visualise le processus de formation.
apprentissage profond PDE NIP PyTorch calcul scientifique
Les équations aux dérivées partielles (EDP) sont le langage de base pour décrire le monde physique : conduction thermique, dynamique des fluides, mécanique quantique, toutes sont dominées par l’EDP. Cependant, la résolution des EDP nécessite souvent des méthodes numériques complexes (éléments finis, différences finies…), ce qui est encore plus gênant pour les zones de formes géométriques irrégulières. Les réseaux de neurones informés par la physique (PINN) donnent une toute nouvelle idée : utiliser le réseau de neurones comme fonction de solution du PDE et utiliser la différenciation automatique comme actionneur de contraintes physiques .
1. Qu’est-ce que le PINN ?
L’idée centrale de PINN : traiter le réseau neuronal non pas comme un « installateur universel », mais comme une représentation de la fonction de solution PDE .
Méthode traditionnelle : étant donné les conditions aux limites et les conditions initiales, approximer la dérivée de la PDE avec des différences numériques.
PINN : approximez la solution de PDE u(x,t) avec un réseau neuronal u_θ(x,t), où θ sont les poids du réseau. Le résidu du PDE est calculé avec précision par différenciation automatique (Autodiff) et ajouté à la fonction de perte.
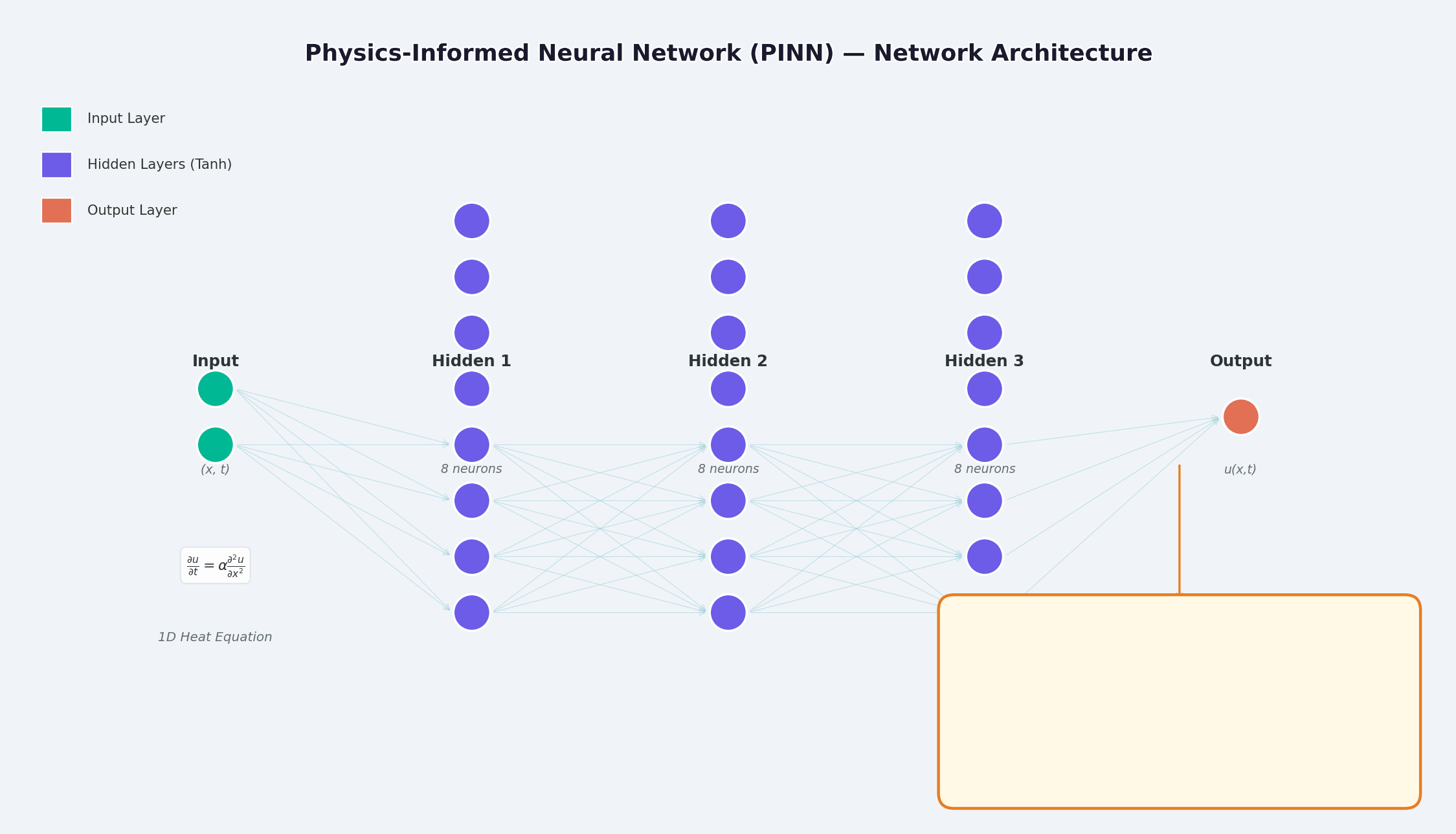
2. Présentation de l’architecture PINN
Comme le montre la figure ci-dessus, la structure du PINN est :
Couche d’entrée : Coordonnées spatio-temporelles (x, t)Couche cachée : Couche entièrement connectée + fonction d’activation (Tanh / Sigmoïde)Couche de sortie : solution de PDE u(x,t)
La principale différence réside dans la conception de la fonction de perte : en plus de la perte d’ajustement des données, une perte de contrainte physique est également ajoutée.
3. Principes mathématiques
3.1 Problème de paramétrage
Prenons l’exemple de l’équation de conduction thermique unidimensionnelle :
vous(-1, t) = vous(1, t) = 0
u(x, 0) = \sin(\pix)
You can't use 'macro parameter character #' in math mode ### 3.2 Fonction de perte La perte totale de PINN se compose de trois parties : \mathcal{L}{total} = \underbrace{\mathcal{L} {PDE}}{\text{Résidus d’équation}} + \underbrace{\mathcal{L} {IC}}{\text{Conditions initiales}} + \underbrace{\mathcal{L} {BC}}_{\text{Conditions aux limites}}
ù é f(x,t) = \frac{\partial u}{\partial t} - \alpha \frac{\partial^2 u}{\partial x^2} \quad \Rightarrow \quad \mathcal{L}{PDE} = \frac{1}{N}\sum {i=1}^{N} |f(x_i, t_i)|^2
You can't use 'macro parameter character #' in math mode > `f(x,t)` est appelé ici <strong>réseau résiduel (réseau physique)</strong>, qui est entièrement construit par différenciation automatique et ne nécessite aucune approximation par différences finies. --- ## 4. Implémentation de PyTorch ### 4.1 Préparation de l'environnement ```bash conda activate carlaTest # carlaTest 已包含: PyTorch 2.4.1 + CUDA + Matplotlib ``` ### 4.2 Code complet ```python import torch import numpy as np import matplotlib.pyplot as plt from matplotlib.animation import FuncAnimation from IPython.display import HTML, Image device = torch.device("cuda" if torch.cuda.is_available() else "cpu") print(f"Running on: {device}") # ============================================================ # 1. 定义 PINN 模型 # ============================================================ class PINN(torch.nn.Module): """Physics-Informed Neural Network""" def __init__(self, layers=[2, 32, 32, 32, 1]): super().__init__() # Xavier 初始化 self.fc = torch.nn.ModuleList([ torch.nn.Linear(layers[i], layers[i+1]) for i in range(len(layers)-1) ]) self.apply(self._init_weights) def _init_weights(self, m): if isinstance(m, torch.nn.Linear): torch.nn.init.xavier_normal_(m.weight) torch.nn.init.zeros_(m.bias) def forward(self, x): for i, fc in enumerate(self.fc[:-1]): x = torch.tanh(fc(x)) # Tanh 激活 return self.fc[-1](x) # 线性输出 # ============================================================ # 2. 精确解(用于对比) # ============================================================ alpha = 0.01 # 热扩散系数 def exact_solution(x, t): """热传导方程解析解: u(x,t) = exp(-π²αt)·sin(πx)""" return np.exp(-np.pi**2 * alpha * t) * np.sin(np.pi * x) # ============================================================ # 3. 训练函数 # ============================================================ def train_pinn(n_iterations=2000, lr=1e-3): model = PINN().to(device) optimizer = torch.optim.Adam(model.parameters(), lr=lr) history = {"total": [], "pde": [], "ic": [], "bc": []} for it in range(n_iterations): # --- PDE 残差点(内部采样)--- x_pde = (torch.rand(256, 1, device=device) * 2 - 1).requires_grad_(True) t_pde = (torch.rand(256, 1, device=device)).requires_grad_(True) # --- 初始条件点(t=0)--- x_ic = (torch.rand(64, 1, device=device) * 2 - 1) t_ic = torch.zeros(64, 1, device=device) # --- 边界条件点(x=±1)--- sign = torch.randint(0, 2, (64, 1), device=device).float() * 2 - 1 x_bc = sign # x = +1 或 x = -1 t_bc = torch.rand(64, 1, device=device) # --- 计算 PDE 残差 --- xt_pde = torch.cat([x_pde, t_pde], dim=1) u = model(xt_pde) # 自动微分:计算 u_t 和 u_xx u_t = torch.autograd.grad(u, t_pde, grad_outputs=torch.ones_like(u), create_graph=True)[0] u_x = torch.autograd.grad(u, x_pde, grad_outputs=torch.ones_like(u), create_graph=True)[0] u_xx = torch.autograd.grad(u_x, x_pde, grad_outputs=torch.ones_like(u_x), create_graph=True)[0] f = u_t - alpha * u_xx # = 0 (当网络收敛到正确解时) # --- 计算各部分损失 --- loss_pde = torch.mean(f**2) # 初始条件损失 u_ic = model(torch.cat([x_ic, t_ic], dim=1)) u_ic_exact = torch.sin(np.pi * x_ic) loss_ic = torch.mean((u_ic - u_ic_exact)**2) # 边界条件损失 u_bc = model(torch.cat([x_bc, t_bc], dim=1)) loss_bc = torch.mean(u_bc**2) # 总损失 loss = loss_pde + loss_ic + loss_bc # 反向传播 optimizer.zero_grad() loss.backward() optimizer.step() # 记录历史 if it % 50 == 0: history["total"].append(loss.item()) history["pde"].append(loss_pde.item()) history["ic"].append(loss_ic.item()) history["bc"].append(loss_bc.item()) return model, history # ============================================================ # 4. 训练 # ============================================================ print("开始训练 PINN...") model, history = train_pinn(n_iterations=2000) print(f"最终损失: {history['total'][-1]:.6f}") ``` ### 4.3 Visualisation : processus de formation ```python # === 训练损失分解动画 === fig, axes = plt.subplots(1, 2, figsize=(14, 5)) def animate(frame): step = max(1, len(history["total"]) // 50) idx = min(frame * step, len(history["total"])-1) axes[0].cla() axes[1].cla() iters = np.arange(len(history["total"])) * 50 pde_ls = history["pde"] ic_ls = history["ic"] bc_ls = history["bc"] # 左图:堆叠面积图 axes[0].fill_between(iters[:idx+1], pde_ls[:idx+1], alpha=0.4, color="#FF6B6B", label="PDE 损失") axes[0].fill_between(iters[:idx+1], np.array(pde_ls[:idx+1])+np.array(ic_ls[:idx+1]), alpha=0.4, color="#4ECDC4", label="初始条件损失") axes[0].fill_between(iters[:idx+1], np.array(pde_ls[:idx+1])+np.array(ic_ls[:idx+1])+np.array(bc_ls[:idx+1]), alpha=0.4, color="#45B7D1", label="边界条件损失") axes[0].set_yscale("log") axes[0].set_xlabel("迭代次数") axes[0].set_ylabel("损失值 (对数坐标)") axes[0].legend(loc="upper right") axes[0].grid(True, alpha=0.3) axes[0].set_title("损失分量演化(堆叠面积图)") # 右图:分线对比 axes[1].semilogy(iters[:idx+1], pde_ls[:idx+1], "r-", lw=2, label="PDE") axes[1].semilogy(iters[:idx+1], ic_ls[:idx+1], "g--", lw=2, label="初始条件") axes[1].semilogy(iters[:idx+1], bc_ls[:idx+1], "b:", lw=2, label="边界条件") axes[1].scatter([iters[idx]], [history["total"][idx]], color="purple", s=100, zorder=5) axes[1].set_xlabel("迭代次数") axes[1].set_ylabel("损失值 (对数坐标)") axes[1].legend(loc="upper right") axes[1].grid(True, alpha=0.3) axes[1].set_title("各损失分量对比") ani = FuncAnimation(fig, animate, frames=50, interval=150) ani.save("pinn_loss_components.gif", writer="pillow", fps=6, dpi=100) ``` --- ## 5. Visualisez les résultats ### 5.1 Processus de convergence de la solution 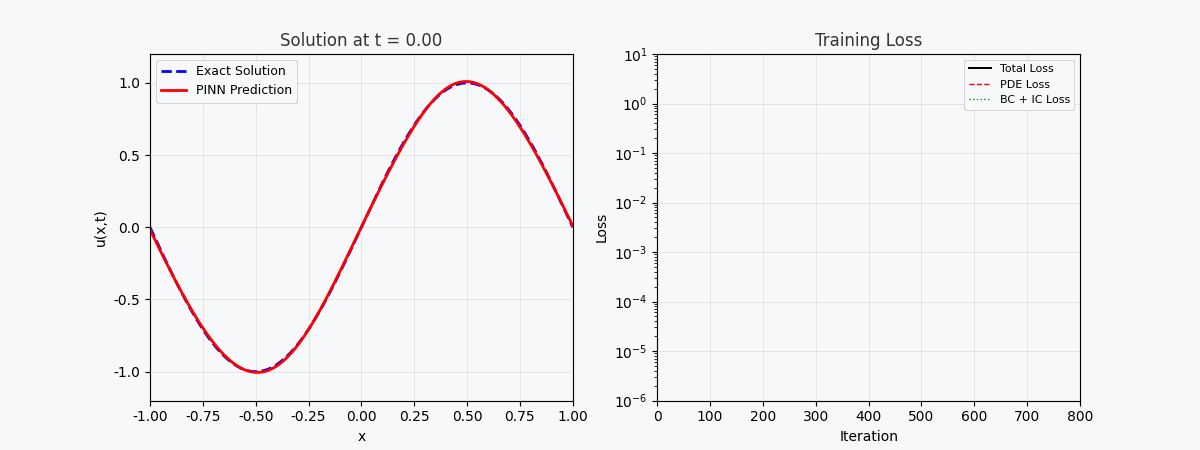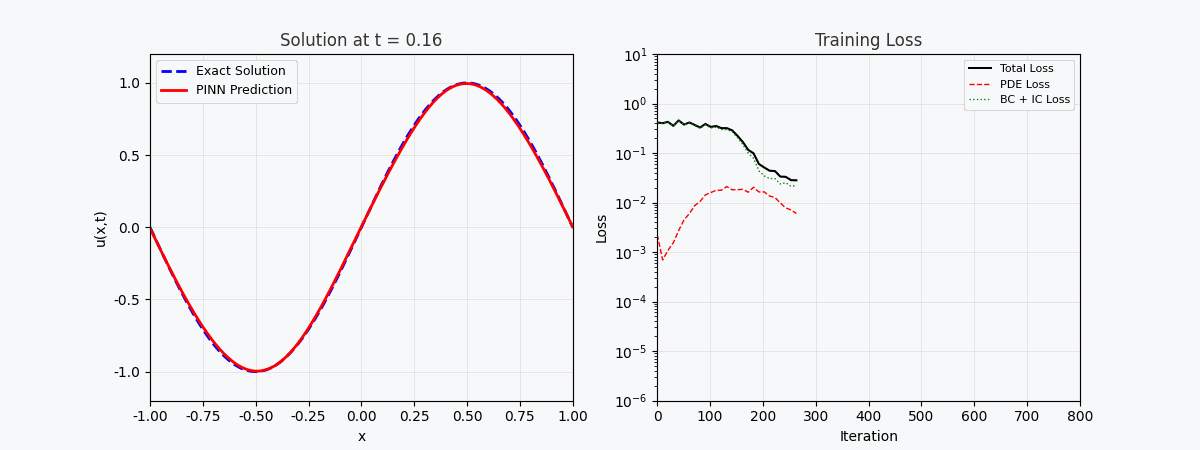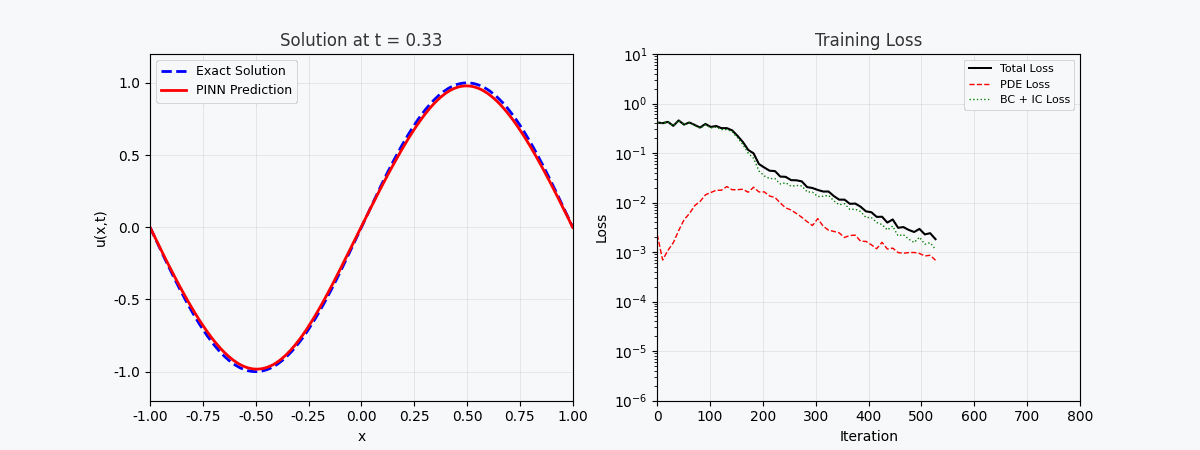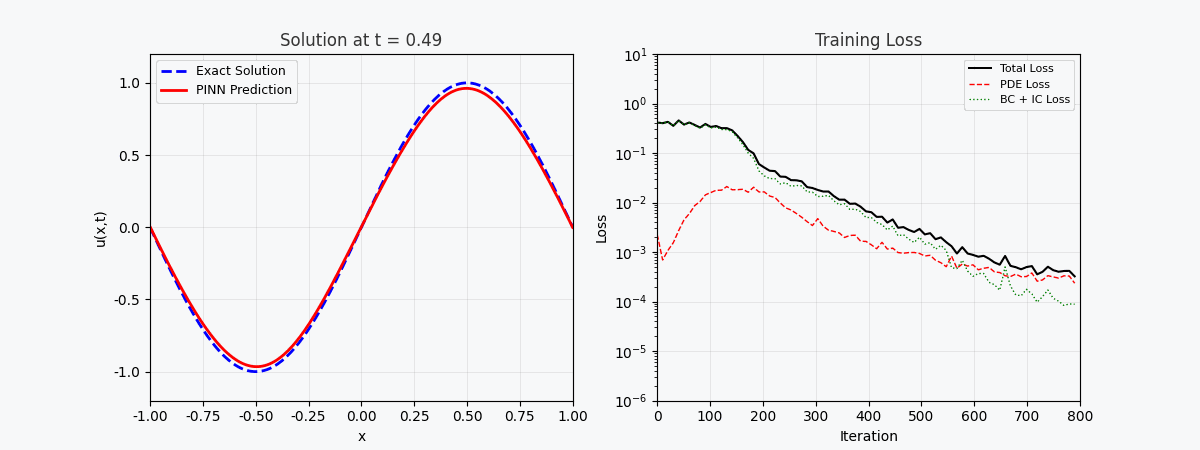 La figure ci-dessus montre le processus par lequel PINN se rapproche progressivement de la solution exacte au cours du processus de formation : - <strong>Image de gauche</strong> : courbe de solution au temps t=0,5, la ligne pointillée rouge est la prédiction PINN et la ligne continue bleue est la solution exacte - <strong>Image du milieu</strong> : perte d'entraînement (échelle logarithmique), vous pouvez voir que les trois pertes diminuent de manière collaborative - <strong>Image de droite</strong> : Champ de solution complet (x,t) prédit par PINN ### 5.2 Décomposition de la fonction de perte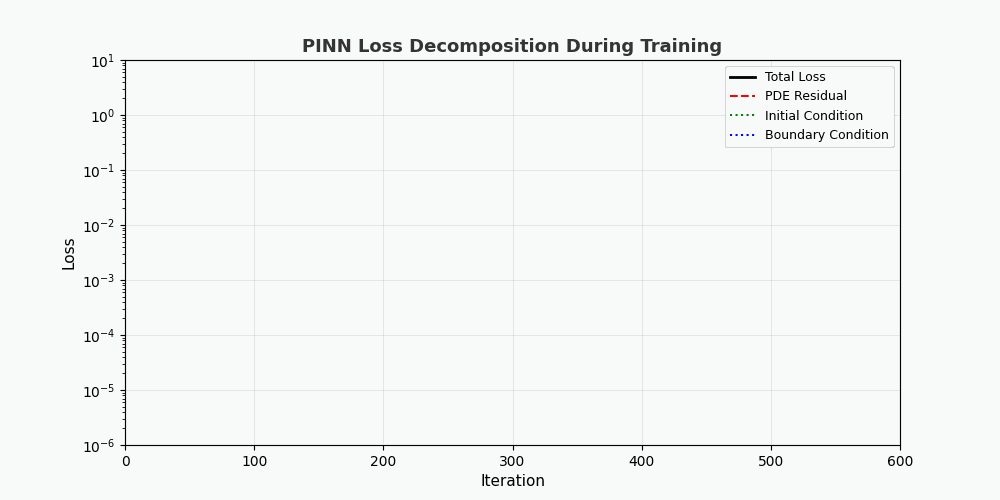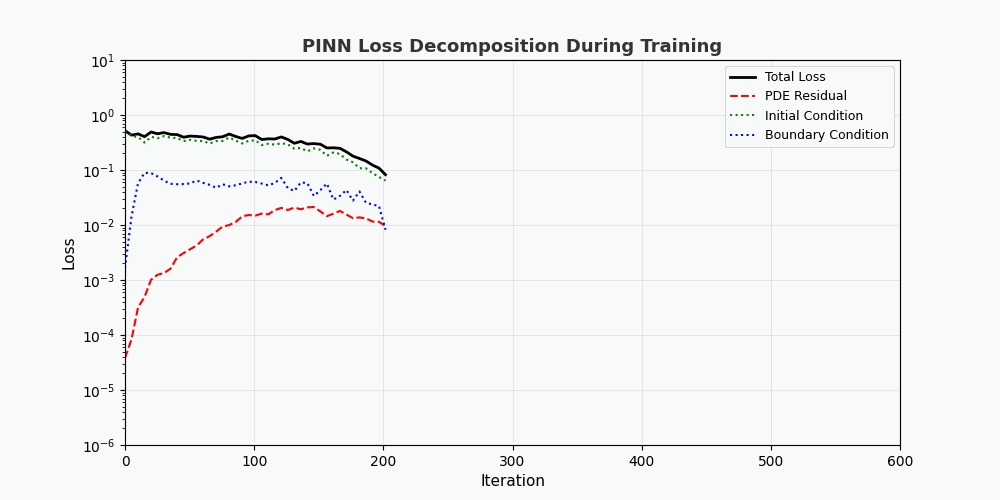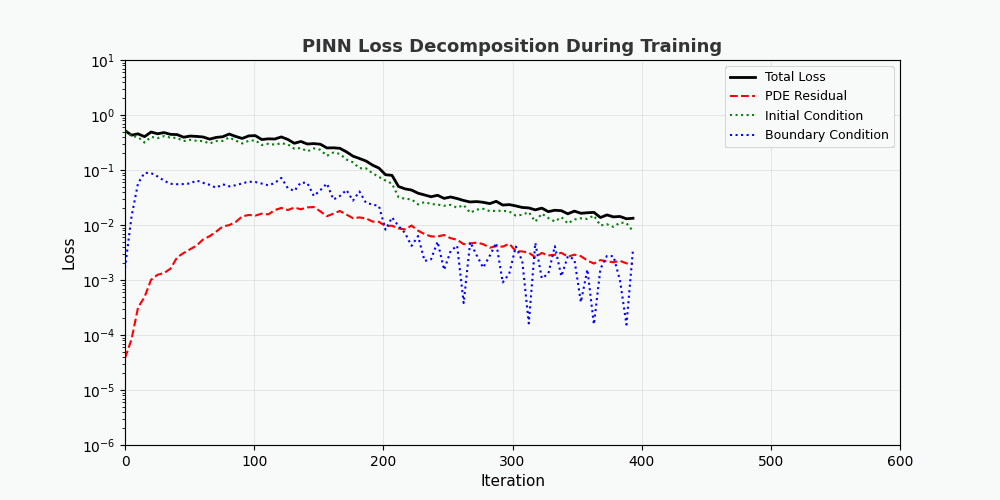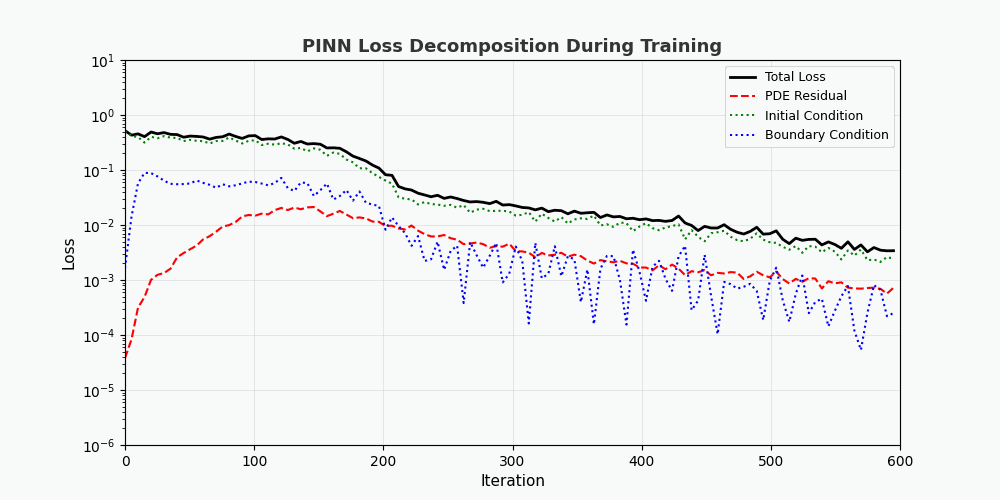 Comme le montre l’animation de décomposition des pertes : - La <strong>perte de PDE (rouge)</strong> a chuté le plus rapidement, indiquant que le réseau a rapidement appris les lois de la physique. - La <strong>Perte de condition aux limites (bleu)</strong> est généralement la plus petite car les contraintes de conditions aux limites sont les plus simples - Les trois pertes finissent par se stabiliser, indiquant que le réseau a convergé --- ## 6. Avantages du PINN | Propriétés | Méthodes numériques traditionnelles (FEM/FDM) | NIP | |------|--------------|------| | Génération de grille | Nécessite une grille fine, une dimensionnalité élevée est difficile | <strong>Aucune grille requise</strong>, échantillonnage aléatoire | | Précision dérivée | S'appuie sur une approximation différentielle, avec des erreurs de troncature | <strong>Différenciation automatique</strong>, précision arbitraire | | Zones irrégulières | Maillage complexe | <strong>Support naturel</strong> pour les géométries arbitraires | | Problème inverse | Re-solveur requis | Optimisation du dégradé <strong>de bout en bout</strong> | | Problèmes de grande dimension | Malédiction de la dimensionnalité | <strong>Évolutif</strong> | --- ## 7. Limites et défis du PINN > Le PINN n'est pas une panacée : il a ses propres limites. ### 7.1 Difficultés d'entraînement - <strong>Mode Collapse</strong> : lorsque le PDE a plusieurs solutions, le PINN ne peut en apprendre qu'une seule. - <strong>Gradient de disparition</strong> : le gradient des dérivées d'ordre élevé (telles que u_xxxx) peut être extrêmement faible dans les réseaux profonds. - <strong>Sensibilité des hyperparamètres</strong> : la profondeur du réseau, le taux d'apprentissage et la stratégie d'échantillonnage ont un impact significatif sur les résultats. ### 7.2 Précision de la solution - Les réseaux de neurones ont une faible précision dans les <strong>solutions haute fréquence</strong> (telles que les solutions d'oscillation) - Les couches limites et les singularités nécessitent des traitements particuliers (échantillonnage adaptatif, expansion de période, etc.) ### 7.3 Efficacité informatique - PINN a tendance à être<strong>plus lent</strong> sur les PDE simples que sur les bibliothèques numériques matures (par exemple FEniCS, COMSOL) - L'utilisation du GPU n'est pas aussi élevée que le code numérique dédié ### 7.4 Axes d'amélioration- <strong>Échantillonnage adaptatif</strong> : échantillonnage multiple dans les zones présentant des erreurs importantes (telles que le raffinement adaptatif basé sur les résidus) - <strong>DeepONet</strong> : Operator Network, apprenez directement les opérateurs de solutions PDE - <strong>Opérateur neuronal de Fourier (FNO)</strong> : opérateur neuronal dans le domaine fréquentiel, meilleur pour les problèmes de grande dimension - <strong>HP-VPINN</strong> : PINN basé sur une forme variationnelle, plus grande précision --- ## 8. Code de formation complet (prêt à exécuter) ```python """ PINN 求解一维热传导方程 conda activate carlaTest python pinn_heat_equation.py """ import torch, numpy as np, matplotlib.pyplot as plt device = torch.device("cuda" if torch.cuda.is_available() else "cpu") alpha = 0.01 class PINN(torch.nn.Module): def __init__(self): super().__init__() self.net = torch.nn.Sequential( torch.nn.Linear(2, 32), torch.nn.Tanh(), torch.nn.Linear(32, 32), torch.nn.Tanh(), torch.nn.Linear(32, 32), torch.nn.Tanh(), torch.nn.Linear(32, 1) ) def forward(self, x): return self.net(x) model = PINN().to(device) opt = torch.optim.Adam(model.parameters(), lr=1e-3) for it in range(2000): x_pde = (torch.rand(256,1,device=device)*2-1).requires_grad_(True) t_pde = (torch.rand(256,1,device=device)).requires_grad_(True) x_ic = (torch.rand(64,1,device=device)*2-1) t_ic = torch.zeros(64,1,device=device) x_bc = (torch.randint(0,2,(64,1),device=device).float()*2-1) t_bc = torch.rand(64,1,device=device) xt = torch.cat([x_pde,t_pde],dim=1) u = model(xt) u_t = torch.autograd.grad(u,t_pde,torch.ones_like(u),create_graph=True)[0] u_x = torch.autograd.grad(u,x_pde,torch.ones_like(u),create_graph=True)[0] u_xx = torch.autograd.grad(u_x,x_pde,torch.ones_like(u_x),create_graph=True)[0] loss = (torch.mean((u_t-alpha*u_xx)**2) + torch.mean((model(torch.cat([x_ic,t_ic],1))-torch.sin(np.pi*x_ic))**2) + torch.mean(model(torch.cat([x_bc,t_bc],1))**2)) opt.zero_grad(); loss.backward(); opt.step() if it%200==0: print(f"Iter {it:5d} | Loss: {loss.item():.6f}") # 测试 x_test = torch.linspace(-1,1,100,device=device).reshape(-1,1) t_test = torch.ones(100,1,device=device)*0.5 u_pred = model(torch.cat([x_test,t_test],1)).cpu().detach().numpy() u_true = np.exp(-np.pi**2*alpha*0.5)*np.sin(np.pi*x_test.cpu().numpy()) plt.figure(figsize=(8,4)) plt.plot(x_test.cpu(),u_true,"b-",lw=2,label="精确解") plt.plot(x_test.cpu(),u_pred,"r--",lw=2,label="PINN 预测") plt.legend(); plt.title("t=0.5 时刻的热传导方程解") plt.savefig("pinn_result.png",dpi=150) print("结果已保存!") ``` --- ## 9. Résumé PINN intègre l'<strong>a priori physique</strong> dans le processus de formation des réseaux de neurones, ouvrant ainsi la voie à un nouveau paradigme d'« apprentissage profond axé sur la physique ». Son innovation principale n'est pas la structure du réseau, mais la conception de la fonction de perte – imposant précisément des contraintes physiques avec différenciation automatique. Malgré des défis tels que des difficultés de formation et une précision limitée, le PINN a démontré une valeur unique dans les scénarios suivants : - <strong>PDE de haute dimension</strong> (catastrophe de dimensionnalité de la méthode traditionnelle) - <strong>Problème inverse</strong> (identification des paramètres, assimilation des données) - <strong>Quantification des incertitudes</strong> (combinée aux méthodes bayésiennes) > Si vous souhaitez approfondir votre exploration, il est recommandé de commencer par la bibliothèque [DeepXDE](https://deepxde.readthedocs.io/), qui encapsule un grand nombre de variantes PINN et de stratégies d'échantillonnage adaptatives. ---<strong>Documents de référence :</strong> 1. Raissi, M., Perdikaris, P. et Karniadakis, GE (2019). *Réseaux de neurones informés par la physique : un cadre d'apprentissage en profondeur pour résoudre des problèmes directs et inverses impliquant des équations aux dérivées partielles non linéaires.* Journal of Computational Physics, 378, 686-707. 2. Lu, L. et coll. (2021). *DeepONet : apprentissage d'opérateurs non linéaires pour identifier des équations différentielles basées sur le théorème d'approximation universelle des opérateurs.* Nature Machine Intelligence, 3(3), 218-229. 3. Li, Z., Kovachki, N., Azizzadenesheli, K., Liu, B., Bhattacharya, K., Stuart, A. et Anandkumar, A. (2020). *Opérateur neuronal de Fourier pour les équations différentielles partielles paramétriques.* Préimpression arXiv arXiv :2010.08895.